


The warmup round is over; I hope you enjoyed it and learned something new in the process!
Here are the explanations for the contest problems and pointers some extra resources that can help you learn more about the respective topics before the main contest. You should also be able to see the solutions of the contest participants and to solve the problems in practice mode.
A: "Distinguishing Unitaries" problems
Here is the editorial for the problems: https://assets.codeforces.com/rounds/1356/A1-A5.pdf.
These problems are published in the Quantum Katas, so that you can see the testing harness used for the problems and use it for testing your solutions in the main contest.
B: Reversible computing
Reversible computing is a branch of quantum computing that deals with expressing classical computations in a reversible manner (i.e., so that the computation has a unique input state for each output state, and inputs and outputs allow a 1:1 mapping). This enables us to perform classical computations (such as arithmetic) on quantum data. This can be done in a systematic way by decomposing the classical computation into primitive classical gates (such as NOT, XOR, OR and AND) and replacing each classical gate with its reversible equivalent (NOT with X gate, XOR with CNOT gate and AND with CCNOT gate), possibly with the use of extra qubits to store intermediary computation results. Let's see how this approach can be applied to these tasks.
1356B1 - Increment
Consider the logic of incrementing a classical number in binary notation:
- Flip the least significant bit.
- If the least significant bit is now 0, increment the rest of the number (i.e., flip the second-least significant bit, check whether it is 0 and apply the same procedure recursively).
We can swap these two steps, so that we would first increment the rest of the number if the least significant bit is 1, and then flip the least significant bit.
To translate these steps to quantum gates,
- If statements translate to controlled gates (remember that all computations have to be done without measurements, so that if the qubit inputs are in superposition, they remain in superposition after the computation as well); we can use
Controlledfunctor to call controlled version ofSolve, with the first argument being the array of control qubits (the least significant bit) and the second argument being the arguments passed to theSolve(the rest of the bits). - Flipping the bit corresponds to applying an X gate to it.
operation Solve (register : LittleEndian) : Unit is Adj+Ctl {
// unwrap LittleEndian type
let qarray = register!;
if (Length(qarray) > 1) {
// increment the rest of the number if the least significant bit is 1
(Controlled Solve)([qarray[0]], LittleEndian(qarray[1 ...]));
}
// increment the least significant bit
X(qarray[0]);
}
1356B2 - Decrement
It is possible to implement the decrement operation in a manner similar to the increment, by analyzing the pattern of bits transformation that happens to a number when it is decremented. But a faster and more neat way involves realizing that decrement is the inverse of the increment operation, or, in quantum computing terms, its adjoint. This means that you can just copy your solution to the previous problem (under a different name, say, Increment) and call Adjoint Increment(register); in your solution.
Here are the resources to learn more about reversible computing and solving problems of this type:
- The Quantum Katas that cover quantum oracles (DeutschJozsaAlgorithm, GroversAlgorithm, SolveSATWithGrover, GraphColoring) and quantum arithmetic (RippleCarryAdder).
- Problems G1-G3 from Winter 2019 — Warmup and problems C1-C3 from Winter 2019 Q# contests.
C: 1356C - Prepare state |01⟩ + |10⟩ + |11⟩
This problem is extremely similar to task 2.3 of the Superposition kata. You can find a detailed explanation of the math used in that solution in the workbook.
To adapt that solution to this problem, you can use the code for that solution exactly as it is to prepare a $$$\frac{1}{\sqrt3}(|00\rangle + |01\rangle + |10\rangle)$$$ state, and as the last step apply an X gate to each of the qubits. This will flip $$$|0\rangle$$$ states to $$$|1\rangle$$$ and vice versa, resulting in the $$$\frac{1}{\sqrt3}(|11\rangle + |10\rangle + |01\rangle)$$$ state, which is exactly our target state.
- This approach to preparing states is called post-selection. You can learn more about it in the "Repeat-Until-Success Examples" section of Q# documentation.
- Another example of preparing a state using post-selection can be found in task 2.7 of the Superposition kata.
D: Quantum classification
Both classification problems in the warmup round were very similar to the problem solved in MLADS tutorial linked from the statements.
If you plot the training data you're given (I used the Python notebook included in the tutorial to do this, with some modifications to load the data from file rather than generate it on the fly), here are the images you'll get:
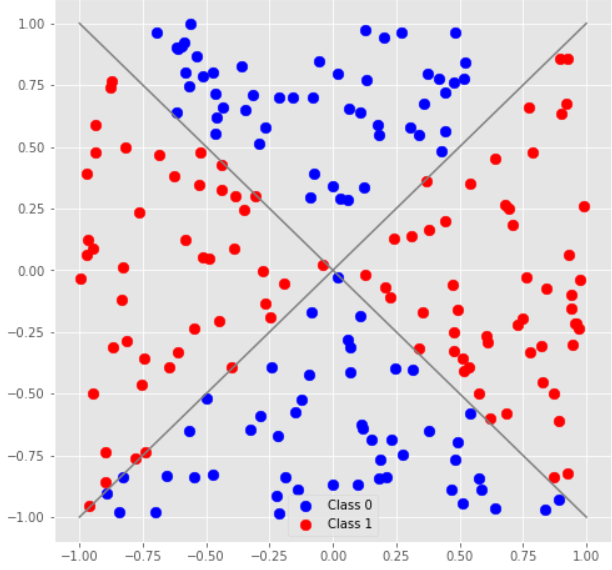
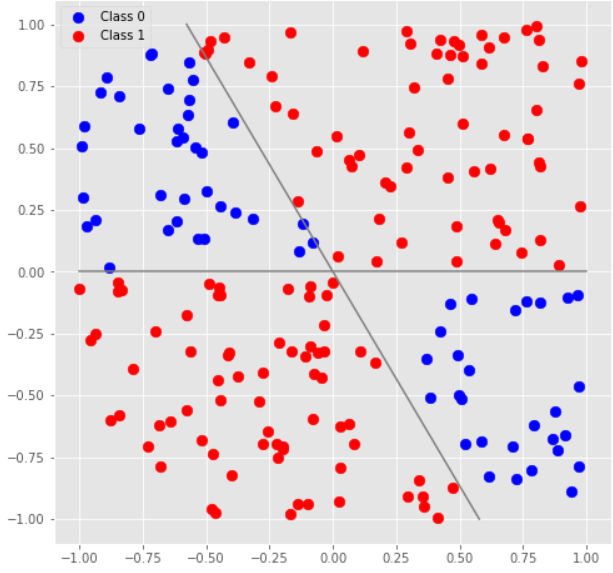
You see the similarity with the tutorial: in all cases the classes are defined by the polar angle of the data point, and not by the distance from the origin. The encoding of the data in the qubit state, described in the "Data Encoding" section of the tutorial, fits this type of problems perfectly, since it preserves the relative magnitudes of the features but discards the information about their absolute magnitudes.
This means the we have only one qubit to build our model upon, which leaves us a very limited choice of gates: Rx, Ry and Rz. The classification process is going to be very simple (and match exactly the one described in the tutorial):
- Encode the data point into the qubit state.
- Apply a rotation gate.
- Measure the result and interpret it.
From here, you can take two approaches to the solution:
Mathematical approach
A model without any gates and with 0 bias is going to perform classification that is exactly the opposite of what we need in D1, with 100% error rate, classifying the vertical "hourglass" area as class 1 and the horizontal "hourglass" — as class 0. To get D1 classification correct, you need to rotate the data by $$$\pi/2$$$ either clockwise or counterclockwise (which corresponds to Ry gate), so that the data from class 0 becomes aligned with the horizontal axis, and the data from class 1 — with vertical. Remember that the angle parameter you pass to the gate is twice the rotation angle you'd use geometrically, so the model parameters end up being (rotation angle = 3.14, bias = 0.0).
The first step to solve D2 is to rotate the data as well, so that middle axis of class 0 is aligned with the horizontal axis — we'll need a $$$\pi/6$$$ geometric rotation, or $$$\pi/3$$$ parameter for Ry gate. However, this time we'll also need to tweak the bias to modify the width of the area that is classified as class 0. Some experimentation or a geometric representation will show that bias = 0.25 allows to achieve this.
Software engineering approach
Alternatively, you can train the model using the provided library to learn the rotation angle and the bias. Most frequently asked question here was tweaking the hyperparameters of the training process so as to speed up the learning. To improve the learning speed and push the model away from the starting parameters, I had to increase LearningRate parameter and reduce Tolerance, as you can see in this code. You can find the list of hyperparameters available to the training process in the code comments here.
The most frequent cause of runtime error verdicts on these two problems was using the more complicated model structure from the library documentation example, rather then the simpler and the more suitable model structure from the tutorial. You have to make sure that the qubits you're referencing in your model will actually be used to encode the data; in this case the data has 2 features and there is no preprocessing to engineer more features, so those 2 features will be encoded in the state of 1 qubit, and referencing qubit with index 1 will cause a runtime error. 3 or 4 features will be encoded in 2 qubits, 5-8 — in 3 qubits and so on, the number of qubits used is the power of the nearest power of two greater than or equal to the number of features.
In the main round of the contest we'll take a closer look at how to use feature engineering to build and train more complex models.







Very good explanation of solutions. Nickolas, you are doing a great job here.
Can someone provide me a good resource to learn about adjoint and controlled since I'm having a hard time getting it from the QDK. I want few example codes. I tried doing previous warmups and contest but want some more.
Have you checked the Quantum Katas? They have a lot of examples on controlled, slightly fewer on adjoint but adjoint is a much simpler concept.
Yes that's a good resource was checking the same right now. Hope to do better in the main contest. Thanks.
You could read a book I was facing the same problem I read the book Dancing with QUbits... Also, could u help me understand the QUantum KAtas... I am not able to understand how to learn something from that...
Since the warmup didn't have problems on Oracles and Unitary transformations, does that mean the main round won't have them too?
Not necessarily. The warmup round helps you prepare for the main round and introduces the new types of problems, but not necessarily repeats the previosly seen types of problems.
when can we expect editorial for D problems... I think it will be helpful since especially because many people have directly hardcoded their answers instead of training the model
Sorry, juggling prep of the next batch of problems with writing editorials for the previous one... I'll try to summarize it tonight, but basically I used the code from the MLADS tutorial on the different set of data, there is no big secret about it.
Thank you for the tutorial.
But, I cannot understand the solution of problem A5, "Distinguish Z from -Z" There are two questions as follows;
1) How can I make -Z gate in Q#. I want to test the code, but I don't know how to create -Z gate in Q#.
2) What is the difference between |1> and -|1> ? Someone said that it is diffent in phase. Another person said that I should know about that this is a waveform. But, I cannot understand.
I searched for the answer for two days but I could not find good explanation. For me, |1> and -|1> is the same in Bloch sphere representation. I can see the difference in matrix and ket notation. But, I cannot understand the meaning.
Is there any good explanation or presentation or video about this issue? I really want to understand it.
Since I don't understand the phase, I also cannot understand why the answer measures the qubit of control part. I vaguely assume that it is due to entanglement, but I really don't undertand why this works.
For one qubit, you have two amplitudes: for |0> and for |1>. Each is a complex number and thus has a phase (argument/angle/etc.). However, it is impossible to distinguish phase absolutely (*global* phase): 1/sqrt(2) (|0> + |1>) is indistinguishable from e.g. 1/sqrt(2) (i|0> + i|1>). You can only distinguish relative phase, which is phase difference between |1> and |0>.
The trick with A5, is that you are given a gate, not just two states to distinguish. And due to the quantum magic, controlled version of -Z is easy to distinguish from controlled Z.
PS: as Nickolas wrote, -Z can be implemented as XZXZ
-Z is XZX — XZXZ adds a global phase of -1.
Documentation says Complex should have named fields:
But I get an error
Do I have a wrong version or ... ?
Also, ComplexPolar::Radius/Phase don't work as well...
Uh, seems that this page in the docs converged from the actual implementation. Complex type has fields Real and Imag, and ComplexPolar — Magnitude and Argument. The actual field names didn't make it to the docs because of the same issue as this one.
Works, thank you!
Would be nice to have getters as functions, to use in e.g. Mapped as:
For D1 and D2, my model always results in one of the parameter starting points, instead of being in between or something. Am I doing something wrong or is this supposed to happen? And if this is supposed to happen, how am I supposed to get the correct answer?
I had the same issue here, maybe that helps?
Dude you are a life saver, thanks!
By the way, this is a very useful tool that allows you to "play around" with quantum circuits and algorithms, helping you design solutions for this contest:
https://algassert.com/quirk
Another stupid question, about Measurement Kata 1.15
How are these states orthogonal? The inner product
But the solution seems to distinguish them well. What am I missing?
UPD: Got it, when transforming $$$|S_1\rangle$$$ to $$$\langle S_1|$$$ I forgot to conjugate. $$$\overline{w}w^2 + \overline{w^2}w = -1$$$ so the inner product is indeed 0.
Is there any convenient way to load data from the JSON to Q# program? Or I have to use python for the machine learning task?
You have to load data using a classical programming language and then pass it to the entry point of the Q# code. Q# is a domain-specific language and doesn't support general-purpose features like reading from file.
I see. Thank you for the quick reply. I have another small question. I was trying to run the example in "ExploringQuantumClassificationLibrary.ipynb" from "MLADS2020-QuantumClassification". But stuck at "import Microsoft.Quantum.Kata.QuantumClassification as QuantumClassification ". It says "ModuleNotFoundError: No module named 'Microsoft'". I am a bit confused. Is there any python package I am missing? How should I install this module?
Please follow installation instructions from the tutorial.
Is there way to allocate two qubits in the |01⟩ state?
No, but you can always allocate two qubits in the |00⟩ state and change their state to |01⟩.
Using X gate for the second qubit?
Yes
I don't quite understand how the classifier architecture works. I prepared data containing only basis vectors, with label "0" if they are x-basis vectors and "1" if they are y-basis vectors. I'm expecting that a circuit model with no gates and with 0 bias will have 100% accuracy. However, this isn't what happens. Instead, all vectors are classified as "0." So, what went wrong here?
Have you tried to classify the same data with a model which has one gate with 0 rotation angle? If that fixes it, might be this bug manifesting.
Yes, the single gate circuit works. Thanks. So it seems I understood the architecture right, I just got really confused by that bug manifesting.
I'm still confused about A4 Z and -Z.
Why does controlled -Z change (|0> + |1>)*|0> to (|0> — |1>)*|0> rather (|0> + |1>)*(-|0>)?
Why does controlled -Z change the control bit?
Thanks
Remember that all gates are linear, so you can reason about their effect on superposition states using their effect on basis states.
Controlled (-Z)(|0⟩ + |1⟩)|0⟩ = Controlled (-Z)|0⟩|0⟩ + Controlled (-Z)|1⟩|0⟩ = |0⟩|0⟩ + |1⟩(-Z)|0⟩ = |0⟩|0⟩ — |1⟩|0⟩ = (|0⟩ — |1⟩)|0⟩