


If you are struggling with the right track and a 10-min read for Operating systems from beginning to end, you're at the right place. Even I am not sure where to start, but we would figure it and if you are reading this, I have successfully completed these notes or at least am on right track.
Let's start our struggle for OS:
The Track
I found many resources to learn, let's just list all: (Galvin Concise PPTs)[https://www.os-book.com/OS9/slide-dir/index.html]: These were great but I felt that these are a little bit too much, so here are the chapters we would do:
- Processes
- Threads
- Process Synchronization
- CPU Scheduling Algorithms
- Deadlocks
- Main memory
- Virtual memory
- Virtual Machines
I am skipping the introduction of OS for now as it was not that important, this is going to be a fast article that works like a last night dose.
Processes
Processes are a program in execution. It has its own memory which is divided into four parts: Text, Data, Heap, and Stack.
Process, as the name suggests, have different states (just like making a joint). Here is a diagram which says it all:
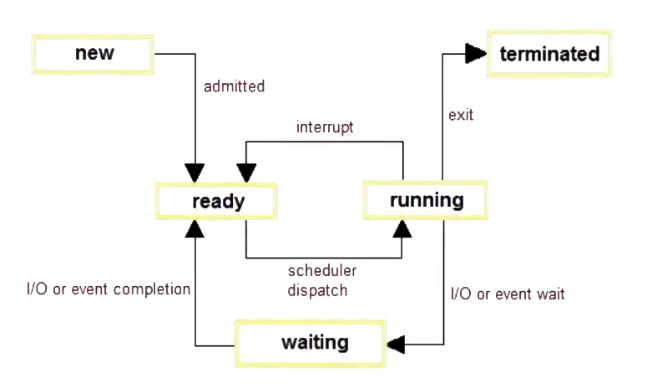
Process Control Block(PCB)
It is a data structure that stores all information about a process.
Process Scheduling Queues
This handles the order of execution of the process. We have different queues for different states. When the state of a process is changed, it is simply detached from the current queue and added to its new state's queue.
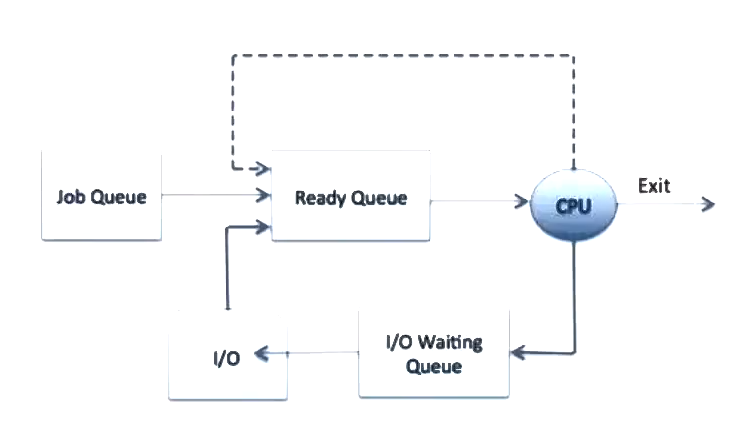
Schedulers
There are three types of schedulers, long term, short term, and mid term schedulers.
Interrupts and Context Switch
An interrupt is like a signal to stop the current process and allow the higher priority process(the process causing the interrupt) to execute. But what happens to the previous process which CPU was executing? It gets saved! When an interrupt occurs, the system needs to save the current context of the process currently running on the CPU so that it can restore that context. It's like a bookmark we have while reading novels. For example, if you are reading a book on data structures and algorithms and suddenly you realize that watching that Avengers 10 min scene would be far more interesting, you place a bookmark and return after 2 hours to resume the same.
The context is saved in the PCB
Also, please note that taking up a new process requires saving the context of the current process and restore the context of the incoming process. This is known as context switch.
Inter-Process Communication
Inter-Process Communication or IPC for short is used for transferring information from one process to another.
We have studied PCBs. We know Process information is stored in PCBs. And we need some sort of a temporary variable to transfer information(like we do to swap two numbers). And we do have two types of mechanisms on this type of principle.
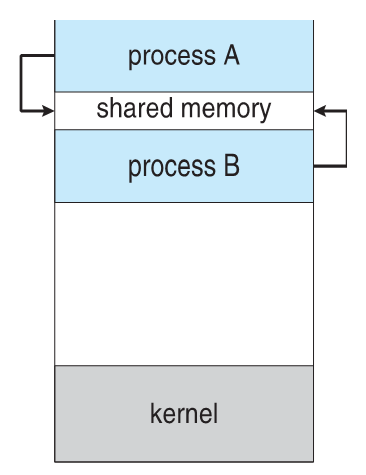
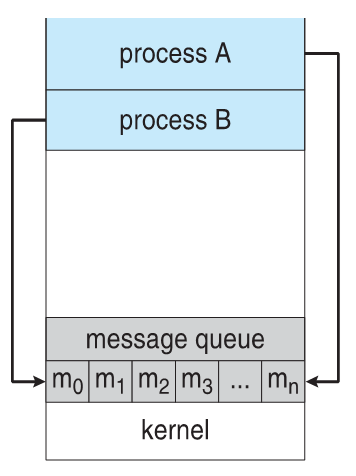
Scheduling Algorithms
Let's start with algorithms.
Process synchronization
Process synchronization problem arises in the case of Cooperative process also because resources are shared in Cooperative processes.
Race Condition
When more than one process is executing the same code or accessing the same memory or any shared variable in that condition there is a possibility that the output or the value of the shared variable is wrong so for that all the processes doing the race to say that my output is correct this condition known as a race condition. Several processes access and process the manipulations over the same data concurrently, then the outcome depends on the particular order in which the access takes place.
Critical Section
A critical section is a code segment that can be accessed by only one process at a time. This code segment is common in many processes and if many processes run simultaneously, we would have a hard time finding the process containing the error, if it happens.

Different Solutions to synchronization problems
1) Disabling Interrupts
We know we can have a race condition if we have some interrupt in a preemptive scheduling algorithm(in a single processor system. In a multiprocessor system, we can have a race condition if two processes on different processors execute the critical section). A process can simply announce that it is entering a critical section and the processor should not interrupt it. Well, it works fine, doesn't it? NO, of course not. This can lead to a lot of problems. Firstly, it is not applicable for multiprocessor systems. Secondly, we cannot give a process the freedom to block the interrupts. It can go on indefinitely inside the critical section, disabling interrupts forever.
2) Locks (or Mutex)
Here we have a lock. We acquire the lock, run a process in the critical section and then release the lock. How it's different from Disabling Interrupts? Here only the process which wants to execute inside the critical section wait, all other processes can still interrupt.
There are two types of implementations:
Software: Peterson solution for two processes and Bakery Algorithm for multiple processes.
Hardware: Generally used, because it's faster. We have test and lock instructions and much more.
Peterson's Solution
As we saw earlier, we need a solution for the critical section of code, as it can lead to anomalies. This solution should satisfy the rules we mentioned before.
3) Semaphores
Semaphore is nothing but an integer variable, and this can be changed by using only these two operations:
- Wait: It is like a decrement operation.
wait(S){
while(S<=0);
S--;
}
- Signal:
Signal(S){
S++
}
Semaphores can be counting or binary(0 or 1).
Binary Semaphores are generally called mutex locks as they provide mutual exclusion.
Counting Semaphores are used to control access to a given resource for multiple processes.
Busy Waiting problem's solution
4) Monitors
Deadlocks

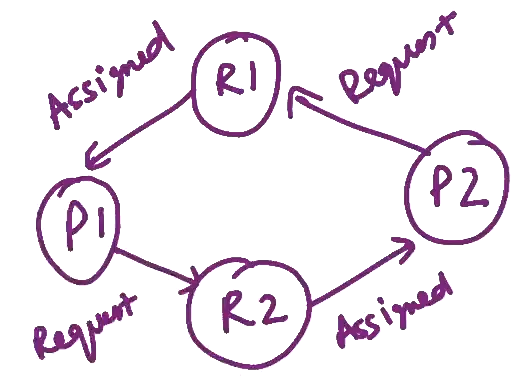
Methods for deadlock prevention
- Deadlock Prevention or Avoidance: We have to prevent any of the four conditions mentioned above.

2) Deadlock detection and recovery
3) Ignore Deadlock and Reboot the system

Problems were some processes along with resources and you have to find the order of execution or which process to remove to avoid deadlocks can be solved by these deadlock resolving techniques. We will be discussing some problems also
Banker's algorithm for avoiding Deadlocks
See the below table: Here initially, we had total resources of type A=10, B=5, C=7. (See it as A printers, B keyboards, C CPUs)
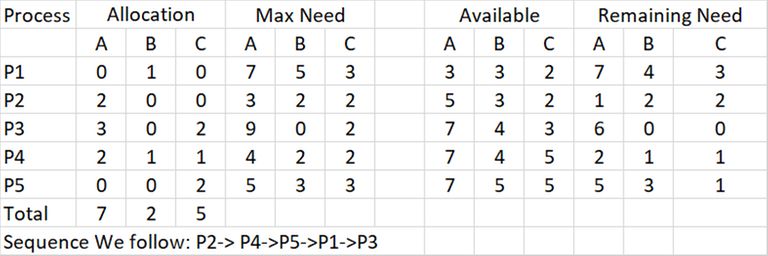
Here is the terminology used here:
Allocation: Resources already allocated by the system
Max Need: Need of resources by processes. (although we saw in the deadlock avoidance that pre-computing how many resources are needed by a process is not possible but still, if we somehow know the maximum need)
Available: Resources available at a particular time. Here initially we had 10 types of A resources but at the point, we came, the system had already allocated some resources leaving us the mentioned resources.
Remaining Need: We already have allocated some resources. The remaining need is just the maximum need-Allocated.
There can be two things here: detection and sequence of processes. We have to output a sequence of processes where deadlock not happens or say it's impossible.
Now, it's very simple from here. We have the remaining need for every process. We just now have to iterate sequentially and see which process we can execute. If it's executable, we can just execute it and we have the allocated resources of that particular process and the process is executed completely. If we come in a situation where we can't execute any process, we welcome the deadlock.
I will be making a Codeforces problem also on it. You can visualize this as a completely greedy algorithm. But as far as the practical application of this algorithm goes, as we saw previously also, we cannot have the max need of processes. We don't know which process wants what resource and for how long and thus, it's not that practical.
Threads
We saw in types of OS(in the introduction at the start of the blog) that we have multithreading as well. We have multiple threads running in an interleaved fashion inside a process. The foremost advantage is the increased responsiveness of the CPU. A thread is the smallest unit assignable to the CPU.

Types of Threads
User Level Thread: A process is creating multiple threads and the kernel is not at all aware of these threads being created. Here we don't need to call the OS and there are no system calls involved making it much faster for context switching. But we have both advantages and certain disadvantages as well. We get fast context switching, and very fast creation and termination time because of no involvement of kernel. But if even a single threads make a call that waits, then all of the other threads in the process have to wait for that call to complete. This is because the call would be made to kernel obviously, and kernel considers the thread as the whole process and would not entertain another call of the same process thread.
Kernel Level Threads: Kernel knows and manages the threads. OS kernel provides system calls to create and manage threads. Kernel Level threads require the involvement of the kernel, which means that you have to do a MOR switch(Google it), you need to go from User space to the kernel space, and then you need to do the switch. And then we have to schedule some other thread as well.
Difference between the two
| Feature | User Level Thread | Kernel Level Threads |
|---|---|---|
| Management | In User space | In kernel space |
| Context Switching | Fast | Slow |
| Blocking | One thread might block all other threads | A thread block itself only |
| Multicore or Multiprocessor | Cannot take advantage of multicore system. Only concurrent execution on single processor | Take full advantage of the multicore system. |
| Creation/Termination | Fast | Slow |
Mapping of User threads to Kernel threads
- One to One: Most common way, used in common Operating Systems like windows. Every user thread is mapped to one kernel thread. Very similar to a pure kernel thread. They are slower than many to one but we can use multicore systems efficiently here.
Many to One: Many users are mapped to one kernel thread. They can be seen as pure user threads. They do provide fast context switching along with fast creation and termination but we cannot utilize multicore systems and all the threads can be blocked by one thread making a system call.
Many to Many: Very rarely used. Many user threads are mapped to many kernel threads.






Thanks for this! However i think if these all can be provided in pdf form /similar it would be of much more help.
Actually I love the spoiler function of codesforces(
...
)
This enables efficient reading and I love to revise with it afterwards.
thanks, next DBMS please.
Would also like to read some notes on the history of the Seleucid Empire.
Yes, please can you share some? Also of the Greek, Macedonian and the Achamenid empires, if you have. Thank you.
If I could share some I wouldn't ask ;)
Oh never mind, I read it as "Would you like to.."
World history (ed. Zhukov) in 10 volumes, volume 2, page 247
Got the real-world scenario of deadlock from Perfect example of deadlock. lol
kamaal
Btw I use Arch btw
Please fix my Pintos code, I have 12 failed tests, and the due is next Monday
Where is the next part of this?? This is not completed yet