


Generous Kefa — Adiv2
(Authors: Mediocrity, totsamyzed)
Consider each balloon color separately. For some color c, we can only assign all balloons of this color to Kefa's friends if c ≤ k. Because otherwise, by pigeonhole principle, at least one of the friends will end up with at least two balloons of the same color.
This leads us to a fairly simple solution: calculate number of occurrences for each color, like, cntc.
Then just check that cntc ≤ k for each possible c.
Complexity: O(N + K)
Godsend — Bdiv2
(Author: Mediocrity)
First player wins if there is at least one odd number in the array. Let's prove this.
Let's denote total count of odd numbers at T.
There are two cases to consider:
1) T is odd. First player takes whole array and wins.
2) T is even. Suppose that position of the rightmost odd number is pos. Then the strategy for the first player is as follows: in his first move, pick subarray [1;pos - 1]. The remaining suffix of the array will have exactly one odd number that second player won't be able to include in his subarray. So, regardless of his move, first player will take the remaining numbers and win.
Complexity: O(N)
Leha and function — Adiv1
(Author: Mediocrity)
First of all, let's understand what is the value of F(N, K).
For any subset of size K, say, a1, a2...aK, we can represent it as a sequence of numbers d1, d2...dK + 1, so that d1 = a1, d1 + d2 = a2, ..., 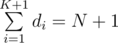 .
.
We're interested in E[d1], expected value of d1. Knowing some basic facts about expected values, we can derive the following:
E[d1 + ... + dK + 1] = N + 1
E[d1] + ... + E[dK + 1] = (K + 1)·E[d1]
And we immediately get that 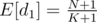 .
.
We could also get the formula by using the Hockey Stick Identity, as Benq stated in his comment.
Now, according to rearrangement inequality, 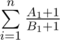 is maximized when A is increasing and B is decreasing.
is maximized when A is increasing and B is decreasing.
Complexity: O(NlogN)
Leha and another game about graph — Bdiv1
(Authors: 244mhq, totsamyzed)
Model solution uses the fact that the graph is connected.
We'll prove that "good" subset exists iff - 1 values among di can be changed to 0 / 1 so that 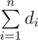 is even. If the sum can only be odd, there is no solution obviously (every single valid graph has even sum of degrees). Now we'll show how to build the answer for any case with even sum.
is even. If the sum can only be odd, there is no solution obviously (every single valid graph has even sum of degrees). Now we'll show how to build the answer for any case with even sum.
First of all, change all - 1 values so that the sum becomes even.
Then let's find any spanning tree and denote any vertex as the root. The problem is actually much easier now.
Let's process vertices one by one, by depth: from leaves to root. Let's denote current vertex as cur.
There are two cases:
1) dcur = 0
In this case we ignore the edge from cur to parentcur and forget about cur. Sum remains even.
2) dcur = 1
In this case we add the edge from cur to parentcur to the answer, change dparentcur to the opposite value and forget about cur. As you can see, sum changed its parity when we changed dparentcur, but then it changed back when we discarded cur. So, again, sum remains even.
Using this simple manipulations we come up with final answer.
Complexity: O(N + M)
On the bench — Cdiv1
(Authors: Mediocrity, totsamyzed)
Let's divide all numbers into groups. Scan all numbers from left to right. Suppose that current position is i. If groupi is not calculated yet, i forms a new group. Assign unique number to groupi. Then for all j such that j > i and a[j]·a[i] is a perfect square, make groupj equal to groupi. Now we can use dynamic programming to calculate the answer.
F(i, j) will denote the number of ways to place first i groups having j "bad" pairs of neighbors.
Suppose we want to make a transition from F(i, j). Let's denote size of group i as size, and total count of numbers placed before as total.
We will iterate S from 1 to min(size, total + 1) and D from 0 to min(j, S).
S is the number of subsegments we will break the next group in, and D is the number of currently existing "bad" pairs we will eliminate.
This transition will add T to F(i + 1, j - D + size - S) (D "pairs" eliminated, size - S new pairs appeared after placing new group).
T is the number of ways to place the new group according to S and D values.
Actually it's 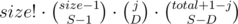 . Why? Because there are
. Why? Because there are 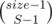 ways to break group of size size into S subsegments.
ways to break group of size size into S subsegments.
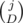 ways to select those D "bad" pairs out of existing j we will eliminate.
ways to select those D "bad" pairs out of existing j we will eliminate.
And 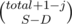 ways to choose placements for S - D subsegment (other D are breaking some pairs so their positions are predefined).
ways to choose placements for S - D subsegment (other D are breaking some pairs so their positions are predefined).
After all calculations, the answer is F(g, 0), where g is the total number of groups.
Complexity: O(N^3)
Destiny — Ddiv1
(Authors: Mediocrity, totsamyzed)
We will use classical divide and conquer approach to answer each query.
Suppose current query is at subsegment [L;R]. Divide the original array into two parts: [1;mid] and [mid + 1;N], where 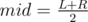 . If our whole query belongs to the first or the second part only, discard the other part and repeat the process of division. Otherwise, L ≤ mid ≤ R. We claim that if we form a set of K most frequent values on [L;mid] and K most frequent values on [mid + 1;R], one of the values from this set will be the answer, or there is no suitable value.
. If our whole query belongs to the first or the second part only, discard the other part and repeat the process of division. Otherwise, L ≤ mid ≤ R. We claim that if we form a set of K most frequent values on [L;mid] and K most frequent values on [mid + 1;R], one of the values from this set will be the answer, or there is no suitable value.
K most frequent values thing can be precalculated. Run recursive function build(node, L, R). First, like in a segment tree, we'll run this function from left and right son of node.
Then we need K most frequent values to be precalculated for all subsegments [L1;R1], such that L ≤ L1 ≤ R1 ≤ R and at least one of L1 and R1 is equal to 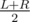 .
.
We will consider segments such that their left border is mid in the following order: [mid;mid], [mid;mid + 1], ...[mid;R]. If we already have K most frequent values and their counts for [mid, i], it's rather easy to calculate them for [mid, i + 1]. We update the count of ai + 1 and see if anything should be updated for the new list of most frequent values.
Exactly the same process happens to the left side of mid: we are working with the subsegments in order [mid;mid], [mid - 1;mid], ..., [L;mid].
Now, having all this data precalculated, we can easily run divide and conquer and get the candidates for being the solution at any [L;R] segment. Checking a candidate is not a problem as well: we can save all occurrences in the array for each number and then, using binary search, easily answer the following questions: "How many times x appears from L to R?".
Complexity: O(KNlogN)
In a trap — Ediv1
(Author: Mediocrity)
The path from u to v can be divided into blocks of 256 nodes and (possibly) a single block with less than 256 nodes. We can consider this last block separately, by iterating all of its nodes.
Now we need to deal with the blocks with length exactly 256. They are determined by two numbers: x — last node in the block, and d — 8 highest bits. We can precalculate this values and then use them to answer the queries.
Let's now talk about precalculating answer(x, d). Let's fix x and 255 nodes after x. It's easy to notice that lowest 8 bits will always be as following: 0, 1, ..., 255. We can xor this values: 0 with ax, 1 with anextx and so on, and store the results in a trie. Now we can iterate all possible values of d (from 0 to 255) and the only thing left is to find a number stored in a trie, say q, such that q xor 255·d is maximized.
Complexity: O(NsqrtNlogN)






