


| # | User | Rating |
|---|---|---|
| 1 | tourist | 3985 |
| 2 | jiangly | 3814 |
| 3 | jqdai0815 | 3682 |
| 4 | Benq | 3529 |
| 5 | orzdevinwang | 3526 |
| 6 | ksun48 | 3517 |
| 7 | Radewoosh | 3410 |
| 8 | hos.lyric | 3399 |
| 9 | ecnerwala | 3392 |
| 9 | Um_nik | 3392 |
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 169 |
| 2 | maomao90 | 162 |
| 2 | Um_nik | 162 |
| 4 | atcoder_official | 161 |
| 5 | djm03178 | 158 |
| 6 | -is-this-fft- | 157 |
| 7 | adamant | 155 |
| 8 | awoo | 154 |
| 8 | Dominater069 | 154 |
| 10 | luogu_official | 150 |
|
+200
Merry Christmas! |

|
+142
I recently subscribed to o1 (not the pro version) in the hope of clearing out some undesirable problems in BOJ mashups, and I got skeptical if this AI is even close to 1600. It can solve some known problems, which probably some Googling will also do. However, in general, the GPT still gets stuck in incorrect solutions very well and has trouble understanding why their solution is incorrect at all. So, how did the GPT get a gold medal in IOI? Probably because it was able to submit many times. So, if I give them 10,000 counterexamples, it will eventually solve my problem. Maybe I could also get GPT to do 1600-level results if I gave them counterexamples all the time. In other words, GPT generates solutions decently well, but it is bad at fact-checking. But fact-checking should be the easiest part of this game: You only need to write a stress test. Then why is this not provided on the GPT model? I assume that they are just not able to meet the computational requirements. I don't think the results are fabricated at all (unlike Google, which I believe fabricates their results) and believe even at o1 model GPT can find a good spot, especially with the recent CF meta emphasizing "ad-hoc" problems which are easy to verify and find a pattern. But this is a void promise if it is impossible to replicate in consumer level. I wonder if o3 is any different. |


|
+135
I only believe it if it was tested in a live contest |

|
+130
OpenAI is lying. I bought 1 month of o1 and it is not nearly 1900 rating. It is as bad as me. I think they lie on purpose because they are burning a lot of money and they want people to buy their model. |
|
+119
Literally 1984. |
|
+91
dude even gpt1 was better than you |

|
+90
Anyone know why o1 is rated 1891 here? From https://openai.com/index/learning-to-reason-with-llms/ o1 preview and o1 are rated 1258 / 1673, respectively. |

|
+90
It will be more funny when we see a red coder who can't qualify for ICPC nationals from their university. It's not funny, it happens quite often, for example, at our university( |

|
+87
thanks for guiding me to become red |
|
+75
I have an answer but this margin is to small to contain it. So I posted it in a separate blog: https://codeforces.net/blog/entry/137488 TL;DR: GCC 7 (32-bit) bad |

|
+73
From the presentation we know, that o3 is significantly more expensive. o1-pro now takes ~3 minutes to answer to 1 query. based on the difference in price for o3, o3 is expected to be like 40-100?(more???) times slower. CF contest lasts at most 3 hours. How can o3 get to 2700 if it will spend all the time on solving problem A? It's very interesting to read the paper about o3, and specifically how do they measure its performance. |

|
+65
I'll wait until it starts participating in live contests and having Red performance |

|
+64
For E, I found this paper which solves a slightly more general problem of coloring a complete bipartite graph into the minimum number of colors such that each color is a forest. |

|
+57
Taking out from the poor to give to the rich, don't let Luigi Mangione see this LOL. |

|
+55
How to increase time limit? |

|
+54
I will personally volunteer myself as the first human coder to participate in the inevitable human vs AI competitive programming match. |
|
+53
It is simply worth increasing the stack in such situations. For example, if you double the stack, then the solution works: 297356923. C++ on Codeforces uses 256 MiB by default, in my solution I increased my stack to 512 MiB. |
|
+53
where is tourist in magic |

|
+52
This round makes me wishing to stop playing Identity V |

|
+51
So what supports their claim of "Elo 2727"? (Apologies if it's included in the video cuz I donot have trivial access to youtube) Last time they claimed o1-mini to be CM level but it could solve only hell classic problems. |

|
+48
Maybe, codeforces should allow some accounts from OpenAI to participate unrated in the competitions? MikeMirzayanov what do you think? |
|
+48
Technology advancements alone will not end online contests. Repeated human dishonesty may deteriorate them. Other uses, such as support for problemsetting among others, may improve them. It's up to people to understand that Competitive Programming is a sport that should be played by respecting rules, and not exploit it as a chance to add another line on their resume. |

|
+46
:'(
|

|
+46
I have recently been spammed by team invites from a user I didn't know and realized how this could be exploited to check if someone has you on their friendlist. (I am not saying you should do this). Lets say you want to check if you are on my friendlist:
|
|
+45
I think the $$$O(n)$$$ solution for C is quite interesting. Why not split it into a C2? |

|
+45
The tasks have been published. You may upsolve the problems and view the specific scoreboard for each contest here. |

|
+45
for F you can solve in $$$O(n \log n)$$$ as follows. Observe that when checking for $$$2^k$$$, only sets with size at least $$$2^k$$$ can possibly work, so delay building them until the size is $$$2^k$$$. With this, it is reasonable to use just an array of size 2^k to store the frequecny array. Insetad of merging two sets in time $$$set constnat * min(|A|,|B|)$$$, we can merge this in exactly $$$2^k$$$. A simple amortization will show that this process is $$$O(n)$$$ for each target power of two. So this part works in $$$O(n log n)$$$. We also have to maintain the maxmium size of all working sets. This costs $$$O(X log X)$$$ for $$$X$$$ at most the number of built set, with the log from constnats of map. Notice that when checking for $$$2^k$$$, $$$X$$$ is bounded by $$$\frac{n}{2^k}$$$. Suming this over $$$k$$$, this part is also $$$O(n \log n)$$$. Edit: I forgot that we you process queries, the same already built set can be moved in/out of working sets, so unfortunately the last seemingly easiest part is actually the slowest at $$$O(n log^2 n)$$$ I don’t see a good way to save the log in this task. Second edit: it turns out saving this last log isn’t as bad as I thought. It is not a true savings, but vEB tree (rather, the practical base 64 variant) allows this final part to be done in O(n log n log log n) overall |
|
+45
hm, o1-ioi is only 1807 in the link I shared though |
|
+44
Pls use spoiler, this comment is unnecessarily log. |

|
+40
Is this a real life? |

|
+39
I doubt that AI can do better math research than humans 5 years later. |

|
On
raoxj →
Performance Ratings vs Ratings of Solvable Problems for the Recent GPT Models, 13 hours ago
+37
It's interesting how AI might have a significantly easier time competing on either codeforces or atcoder, depending on how accurate it will be. Very inaccurate: atcoder would be easier. It might make hundreds of submissions and be the slowest participant to solve N problems. But still get full score for those N problems and be ahead of anyone solving N-1. While barely getting any points on CF due to massive wrong submission penalty. Very accurate: codeforces would be easier. Solving N problems without any point decay might even put it ahead of people solving N+1 in addition to being the first to solve N. |

|
On
raoxj →
Performance Ratings vs Ratings of Solvable Problems for the Recent GPT Models, 12 hours ago
+37
Phrased another way, CF ratings for generative models are not equivalent to CF ratings for humans. Time is a big bottleneck for humans (e.g. to think of promising lines of thought, to write out code, to debug, to possibly change approaches, to possibly invest time in writing and running a brute force program to check for correctness), but likely not as much for generative models (e.g. writing code happens quickly, more candidate ideas can be tried out, the opportunity cost in trying to do the harder problems is much smaller). If you give the average yellow coder a week to do a two- or three-hour contest and map their solve times proportionately, they'll likely be able to perform at a 2700 level as well. Nevertheless, an LLM performing at the level of a Master is still quite a feat. |
|
+36
Don't curse me bro :( |

|
+36
i think you're not seeing the bigger picture, the implications for the competitive programming are huge. 1) we might lose sponsors/sponsored contests because now contest performance isn't a signal for hiring or even skill? 2) let's not kid ourselves, but a lot of people are here just to grind out cp for a job / cv and that's totally fine. now they will be skewing the ratings for literally everyone. 3) from 2 it may follow that codeforces elo system completely breaks and we'll have no rating? the incentive to compete is completely gone which will further drive down the size of the active community there are many more, i bet you could even prompt chatgpt for them :D |
|
+36
I'm a bit skeptical. o1 is claimed to have a rating around 1800 and I've seen it fail on many div2Bs. |
|
+35
MexForces |
|
+35
Where is the cycle in the DP transition for D coming from? Surely you can just do $$$g(i, j, x) = \text{min}(g(i, j - 1, x), f(i - 1, j) + kx) + a(i, j + x)$$$, and there is no cycle? |
|
+34
Edit: Codeforces DOES pass Original comment: It is because codeforces's judging environment is Windows, and it seems that they don't pass |

|
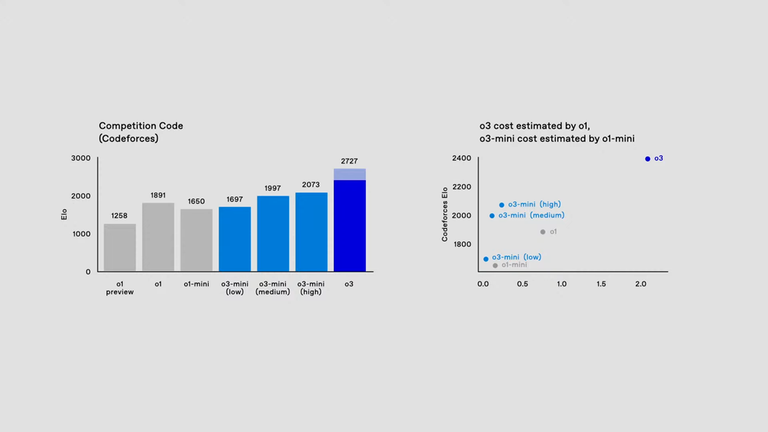
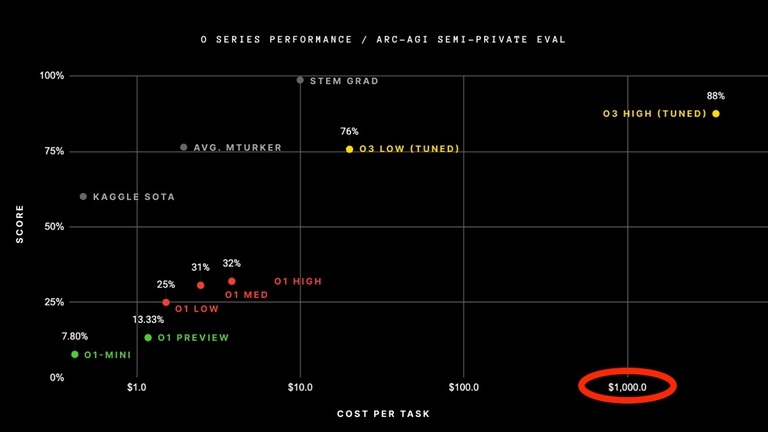
+34
This is not for the Codeforces benchmark but for the ARC-AGI benchmark, where they set a new state of the art. Please watch from https://youtu.be/SKBG1sqdyIU?t=304 for more details. Here's the actual benchmark we're looking for:
According to https://youtu.be/SKBG1sqdyIU?t=670, o3 is actually more cost effective than o1. Here's a comparison based on openai's benchmark (Estimated by my eyes):
|

|
+31
Honestly a min Cartesian Tree is just a fancy way of refering to the classic problem of finding for each element its first lower neighbours on the left/right. Now you can say that each element is the node corresponding to an interval, and all you need to add is to compute the two childs in the tree (which corresponds to the interval splitted by the minimum value), which requires a bit of thinking but no complicated code. Finally to manage the DP in the tree you can do simply dfs using the indices of intervals and never explicitly construct the tree, like you would do in a divide and conquer approach. All in all it might be a complex idea but it can be implemented easily (you can check my submission if you'd like (which is $$$O(nlog^2)$$$ should you wonder)) |

|
+31
b was absolute shit |
|
+30
your comment gave me eternal_happiness |

|
+30
I never enjoyed contests nearly as much as I enjoy solving hard problems offline at my own pace, so I wouldn’t really care if contests were to end entirely.
Soon, we are going to lose this advantage too, and not just in sport programming but all areas of life. |
|
+28
first. B was brutal |

|
+27
No. Over half of the people here (and much more in the whole society) are not genuine CP lovers. They will use AI for malicious purposes and we cannot stop them. |
|
+26
I replicated this problem on my device, the division by zero occurs at line 274, during initialization of global variable This probably has something to do with the order in which compiler initializes static variables, you might wanna look into this. |

|
+26
Why? I'm just using the OS's capabilities. I just create a new thread, give 512 MiB stack memory to it, and order the main thread wait until the one I created completes. If the solution with this technique it does not exceed ML, then it should be legal, I think. |
|
+26
What does the light blue part on o3 mean here? Doesn't seem like the video explained it. |

|
+26
If anyone can cheat, the incentive for cheating is greatly reduced. A clear example is chess, where top engines are publicly available and far stronger than any human. A key difference, however, is that chess has frequent in-person contests that ground ratings. For competitive programming to have a future, in-person contests would need to become more frequent. One upside of intelligent AI is that it could make writing problems for in-person contests much easier. I think another reason many people feel sadness because of this news is tied to the value they get from being able to solve difficult problems. Right now, if you have an algorithm problem of moderate difficulty, say, under 2000, the best course of action is often to ask someone skilled in competitive programming. But if GPT becomes equivalent to a 2700-rated competitor, that role essentially disappears. The "problem-solving skills" you worked hard to develop become little more than trivia, as anyone could achieve similar results by prompting an AI model. |
|
+26
where Tourist |

|
+25
Today I learned that stack size on CF is not unlimited. |

|
+25
Really? Meoww~~~~~~~~ |
|
+25
Well you see, the question of "who asked?" is simply a paradox. Since by asking "who asked?", you are implying that people need to be asked before speaking. However following that logic, you would have needed to have someone grant you permission to say that, because who asked you to say "who asked?" ? Exactly, nobody did, and nobody can ask anyone to give them permission to give you permission because no one asked them. And this perpetual loop never ends, creating a paradox. Created by @veryhungrydinosaur |

|
+25
hell, sometimes I don't believe it's fake until Trump starts trying to sell me his super patriotic signature-signed underwear |
|
+24
Interactive problems are fun to solve. Isn't it? |

|
+24
A vivid example on why you must always submit with Pypy, not Python. |
|
+24
Yes, its binary search. Lets first split the array into 4 equal sized ranges. This is clearly possible since $$$n$$$ is a power of $$$2$$$ and at least $$$4$$$. If we queried these 4 ranges, we would either get back:
This naively takes $$$4$$$ queries for the first part + $$$30$$$ for the binary search which is $$$1$$$ too much. But we can notice that the result for the 4th segment can be uniquely obtained from the query results for the first 3 segments, reducing our total to $$$33$$$ queries. Code — 297544715 |

|
+24
Since the scale is logarithmic, o3 high is pretty close to $10000 |

|
+24
|

|
+23
Problem G will not be interactive. Probably because there will be no problem G. |

|
+23
According to cppreference, the initialization of such [class template] static variables [that aren't explicitly specialized] is indeterminately sequenced with respect to all other dynamic initialization. Unluckily, your To solve this, you can either initialize |
|
+23
Little09 Can you elaborate on the $$$O(n\log^2n)$$$ solution for I2? Idk what block convolution is. |
|
+23
Codeforces Hot News!Wow! Coder chenlinxuan0226 competed in Codeforces Global Round 28 and gained -55 rating points taking place 1293 Share it! |

|
+23
Here's what we exactly should do: make general perception that using AIs in contests is absolutely bad and hate those who use them in contests. In everyday life, we prevent ourselves from doing bad things because we know we shouldn't do bad things, not because it's hard to do bad things. Most of the temptation to use AIs comes from the lack of this perception, because even though using AIs is prohibited now, many people still think "but... it's not really that bad, isn't it?" This is also the case for alts: we're lacking general perception that alts are absolutely bad that we should never make alts. I almost everyday see people advertising that they have alts in public channels without feeling guilty at all. It would be crazy to see similar situations with the AIs. I don't like all those "It's over" comments because that's exaclty what makes the opposite perception. It makes us feel that there's no meaning to have rules in CP anymore and thus increases the temptation to use AIs. What we should do is to stop self-ruining the atmosphere and focus on continuing the community as people who love CP. Do not give credits who do bad things against the rules. As the broken windows theory suggests, we can only hope that some good effort is done to catch the AI users, so that this temptation does not spread out to more and more people. |
|
+22
wdym, if there is no problem G then the proposition "Problem G of this contest is interactive" is vacuously true 🤓 |

|
+22
You all are missing a very important thing, o3 takes $100+ per task to compute
|
|
+21
The proof of this is that the subgraph with edges of one color must form a forest. Thus each color must have at most $$$2n + m - 1$$$ edges of that color. So in total the number of edges should be at most $$$(2n + m - 1) \cdot n$$$. But there are $$$2mn$$$ edges. Thus |

|
+21
I hate the fact, that I was debugging F for 40 minutes, because I was getting RTEs on test 3. There was some stupid stack overflow; the recursion was returning a big static object (488 bytes), and after changing it to return an 8 byte pointer, it started working; however, my memory usage was under 350MB, so it should have passed initially. |

|
+21
True. I have tested o1 and yet it could barely solve most 1500~1600 tasks. I thought that maybe, since it's a language model, it would be better at solving more standard problems. But well, it also failed miserably in some (note: some, not all) quite well known problems. From what I've seen o1 can easily solve "just do X" type problems, and is pretty decent at guessing greedy solutions (when there is one). My guess is that openAI did virtuals with o1 in a bunch of different contests and claimed it to have the rating of the best performance between all these virtuals. |
|
+20
bro skipped a step from taking the xor of numbers of 5000 digits to finding the optimal solution |
|
+20
I use bfs in problem C.I thought I would get MLE or TLE pending but I passed the testings.:) |

|
+19
You can only be easier to read statement about chess if you're good at chess. |
|
+19
|


|
+19
This is brutally cruel, I got WA because my max query count was $$$34$$$... Why is there the need to outright destroying implementation that simply lacks a bit of thinking that isn't much crucial to the problem idea? (Of course, I am a bit salty, and I don't think I should really blame it coz I upsolved either way, but I feel the "less optimized solutions to pass" intention is quite not-so-there.) |

|
+18
For F, my solution does actually do the updates in the normal order. I maintained for each power $$$k$$$ a set of ranges, where each range stores a frequency array of size $$$2^k$$$, as well as a multiset of the lengths of valid ranges (to get the answer). A range is valid if every element in its frequency array is nonzero. Then each update either modifies or splits $$$\text{log} \, n$$$ ranges. For each power $$$k$$$, find the range that position $$$i$$$ is contained in (or skip if it doesn't exist). If $$$a_i + x$$$ is still within the range, just update its frequency array. Otherwise we need to split it into two ranges. We can use "large-to-small splitting": modify the frequency array of the larger half, then make a new range for the smaller half (if its size is at least $$$2^k$$$). So the total number of frequency array updates per power $$$k$$$ is at most $$$O(q + n \, \text{log} \, n)$$$, so the overall complexity is $$$O((n + q) \, \text{log}^2 \, n)$$$. |
|
+18
Not possible... |

|
+18
I don't think o1 has 1891. I gave him an 1400 problem just now, but he failed to work out it after 20 tries. |

|
+18
I think the announcement has a mistake: It is Luogu Round 210 but not Luogu Round 10. |
|
+17
Can everyone here know this guy's username? At least we can do 0.1 emotional damage to him. |
|
+17
is the recurrence given in the editorial even correct ? |

|
+17
Nice contest! I had fun participating, and it was especially nice to see that the quality of translation has gone up by a lot. Some minor questions (not directly related to the contest, sorry if this is the wrong place to ask!):
I'm looking forward to the day when Luogu offers a completely English interface alongside a Chinese one! The system currently feels somewhat clunky and awkward with the mix of Chinese and English, but it was a lot of fun nonetheless. |

|
+16
I HATE problem E, i'm pretty sure most of the AC just guessed it. |

|
+16
Maybe the problem is that codeforces is passing exactly 256MB and ignoring the problem's memory limit, https://codeforces.net/blog/entry/121114 ? |
|
+16
I also used GCC 7 (32-bit) on the contest yesterday, but my submission passed without any issues: 297315717. Arguably, my code is even worse because I am creating and returning a new After a bit of experimenting, here is what I can share:
The takeaway? I honestly don't know. But I will definitely stick to GCC 14 (64 bit) from now on. |

|
+16
If o3 really has deep understanding of competitive programming core principles I think it also means it can become a great problemsetting assistant. Of course it won't be able to make AGC-level problems but imagine having more frequent solid div.2 contests that would be great. |
|
+16
o1-pro was tested in this contest live https://codeforces.net/contest/2040 and solved E,F (the blog has since been deleted) |

|
+16
|


|
+15
why post this twice? |

|
+15
For F, the constraints don't cut the $$$n \cdot \log^2(a)$$$ solution, but also make it harder for people who are careful. I spent extra time to optimize out a $$$\log(a)$$$ factor just like the editorial because $$$n \cdot \log^2(a) \approx 8 \cdot 10^8$$$. If instead the time limit was greater or $$$a = 10^9 \implies n \cdot \log^2(a) \approx 2 \cdot 10^8$$$, I would definitely go for this solution and not waste time. Since I optimized, I failed to finish F by a few minutes. |

|
+15
It's just luck. |

|
+15
I think this happens because the specific way problems are created and arranged for NOI and CTT is quite different. I don’t have solid proof, but here are a few key differences I’ve noticed:
Another thing to consider is that after NOI, a lot of Chinese participants start pre-university programs at THU or PKU, where they spend a lot of time on college-level courses. That takes away from their training time. |
|
+15
Has anyone seen the AI Trump ads on youtube recently? The advertisers are using Trump's image to sell their "patriotic" products, which I can't imagine is legal. But anyway, the Trump deepfakes are pretty much the real deal at this point, which is crazy (at least to me). I remember a time when deepfakes were so fake that people used to make fun of them and turn them into memes. That was about $$$1-4$$$ years ago. |
|
+15
Do I still have a chance to reach LGM before AI? |

|
+15
Codeforces Hot News!Wow! Coder chenlinxuan0226 competed in Codeforces Round 994 (Div. 2) and gained -160 rating points taking place 4892Share it! |
|
+14
E made me sad. |

|
+14
|

|
+14
this contest was a pain in the ass |
|
+14
Benq do you think it's the end? |
|
+14
cp is P2W at this point |

