


Заметим, что если k > |s|, то выполнить заданное условие невозможно, и ответ -- <<**impossible**>>. Иначе искомая величина равна max(0, k - d), где d -- количество различных букв в исходной строке. Это верно, потому что, в случае, когда k ≤ d, необходимость в изменениях отсутствует. Если же d < k ≤ |s|, то можно заменить k - d букв, которые встречаются более одного раза, на буквы, которых в s нет. Сложность решения: 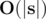
Первым делом заметим, что каждое множество такого вида всегда целиком содержится либо в одной строке, либо в одном столбце.
Пройдемся по каждой строке и по каждому столбцу, посчитаем количество клеток k0, k1 соответствующих цветов.
Просуммируем для всех полученных k * функцию 2k * - 1 (это число непустых подмножеств данного цвета, целиком лежащих в конкретной строке/столбце).
В конце необходимо вычесть из полученной суммы n·m -- количество одноклеточных множеств, которые мы посчитали два раза (один раз в строке и один раз в столбце).
Сложность решения: $\mathbf{O(n \cdot m)}
Посмотрим на сортировку последовательности как на некоторую перестановку P ее элементов. В силу того, что все элементы последовательности различны, эта перестановка задается однозначно.
Разобьем P на простые циклы. Тогда качестве ответа можно взять подпоследовательности, образованные этими простыми циклами.
Больше подпоследовательностей сделать нельзя, так как сортировка подпоследовательности -- это также перестановка, и, если бы последователность ai можно было бы разбить на большее число подпоследовательностей, то существовало бы разбиение перестановки P на большее число простых циклов.
Сложность решения: 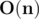
Спросим значения в ячейке start и в 999 других случайных ячейках. Выберем из них наибольшую среди тех, в чье значение меньше или равно x.
Будем идти из нее по порядку по элементам списка, пока не встретим первый элемент больший или равный x, который и будет ответом.
Вероятность того, что этот алгоритм за 2000 действий не найдет нужный элемент равна вероятности того, что среди 1000 предыдущих перед правильным ответом элементов списка не встретится ни одного, который попал в нашу выборку из 999 случайных элементов. Эту вероятность можно оценить как (1 - 999 / n)1000 ≈ 1.7·10 - 9
Вершина-центроид при таких операциях остается центроидом. Если в дереве два центроида, то ребро между ними неизменно.
Компоненты, которые крепятся к центроиду, не могут поменять свой центроид или разделиться. За (размер компоненты * 2) можно превратить ее в ёжик (например превратить ее вначале в бамбук, а потом в ёжик), подвешенный к её центроиду. Доказательство того, что сумму квадратов расстояний меньше сделать нельзя, оставим в качестве дополнительного упражнения для пытливых читателей.
Сложность решения:
Вначале один раз запустим обычную Дейкстру из s. Найдем расстояния и сделаем их потенциалами вершин. Далее на каждый запрос будем пересчитывать все расстояния и делать потенциалы равными этим расстояниям. Чтобы быстро пересчитывать расстояния между запросами заметим, что в графе с потенциалами все расстояния равны 0. Когда мы увеличили у части ребер веса на 1, то в графе c потенциалами все расстояния не превосходят число измененных ребер и можно запустить Дейкстру на массиве за O(V + E).
В начале найдем минимальный набор насыщенных ребер. Для этого создадим новую сеть с тем же набором вершин, но немного другими ребрами.
Для каждого ребра исходного графа, по которому ничего не течет создадим ребро в том же направлении с f = INF пропускной способностью. Для каждого ребра, по которому что-то течет создадим два ребра, одно в том же направлении с f = 1, и одно в обратном c f = INF.
В новой сети найдем минимальный разрез, он будет состоять только из ребер с f = 1, соответствующие им ребра исходного графа и будут искомым минимальным набором.
Если бы минразрез оказался равен бесконечности, то описание, которое нам дали в условии не могло бы быть описанием максимального потока, он был бы гарантированно увеличиваемым.
Теперь достаточно построить ненулевой поток по всем ребрам, по которым это требуется в условии и сделать c = f на ребрах, которые мы решили сделать насыщенными, и c = f + 1 на всех остальных. Рассмотрим ориентированный граф ребер, по которым что-то должно течь.
Лемма: каждое ребро этого графа либо лежит на цикле, либо лежит на пути из истока в сток. В первом случае можно пустить по циклу циркуляцию 1, во втором пустить по пути из истока в сток поток 1. Таким образом, по каждому ребру, по которому должно что-то течь, будет что-то течь.
Доказательство леммы: Предположим обратное. Возьмем такое ребро u->v. Значит, либо нет пути из s в u, либо нет пути из v в t. Пусть верно второе без ограничения общности. Рассморим множество вершин достижимых из v. Если там есть u, то нашелся цикл. Если нет, то это множество плохое, потому что в нем нет t, в него что-то втекает и ничего не вытекает, в корректной сети такого быть не может.


