


I'm very sorry about all the inconvenience, and I would like to bear the blame. Much thanks to those who help me prepare this round. It's not their fault. And much thanks to your participation.
1581A - CQXYM Count Permutations
idea: interlude
preparation: CQXYM
tutorial: CQXYM
Assume a permutation $$$p$$$, and $$$\sum_{i=2}^{2n}[p_{i-1}<p_i]=k$$$. Assume a permutaion $$$q$$$, satisfying $$$\forall 1 \leqslant i \leqslant 2n, q_i=2n-p_i$$$. We can know that $$$\forall 2 \leqslant i \leqslant 2n,[p_{i-1}<p_i]+[q_{i-1}+q_i]=1$$$. Thus,$$$\sum_{i=2}^{2n}[q_{i-1}<q_i]=2n-1-k$$$, and either $$$p$$$ should be counted or $$$q$$$ should be counted. All in all, the half of all the permutaions would be counted in the answer. Thus, the answer is $$$\frac{1}{2}(2n)!$$$. The time complexity is $$$O(\sum n)$$$. If you precalulate the factors, then the complexity will be $$$O(t+n)$$$.
1581B - Diameter of Graph
idea: CQXYM
preparation: CQXYM
tutorial: CQXYM
If $$$m < n-1$$$, the graph can't be connected, so the answer should be No. If $$$m > \frac{n(n-1)}{2}$$$, the graph must contaion multiedges, so the answer should be No. If $$$m=\frac{n(n-1)}{2}$$$, the graph must be a complete graph. The diameter of the graph is $$$1$$$. If $$$k>2$$$ the answer is YES, otherwise the answer is NO. If $$$n=1$$$, the graph has only one node, and its diameter is $$$0$$$. If $$$k>1$$$ the answer is YES, otherwise the answer is NO. If $$$m=n-1$$$, the graph must be a tree, the diameter of the tree is at least $$$2$$$ when it comes to each node has an edge with node $$$1$$$. If $$$m>n-1 \wedge m<\frac{n(n-1)}{2}$$$, we can add edges on the current tree and the diameter wouldn't be more than $$$3$$$. Since the graph is not complete graph, the diameter is more than $$$1$$$, the diameter is just $$$2$$$. If $$$k>3$$$ the answer is YES, otherwise the answer is NO. The time complexity is $$$O(t)$$$.
1580A - Portal
idea: CQXYM
preparation: CQXYM
tutorial: CQXYM
We can enumerate the two corner of the submatrix, calculate the answer by precalculating the prefix sums. The time complexity is $$$O(\sum n^2m^2)$$$. When we enumerated the upper edge and the lower edge of the submatrix, we can calculate the answer by prefix sum. Assume the left edge of the submatrix is $$$l$$$, and the right edge is $$$r$$$. The part of anwer contributed by upper and lower edge are two segments, we can calculate the answer by prefix sums. The middle empty part is a submaxtrix, and we can use prefix sums too. Since we have enumerated the upper edge and lower edge, the left edge part is just about $$$l$$$, and the right part is just about $$$r$$$. Then we enumerate $$$l$$$, the answer of the best $$$r$$$ can be calculated by precalculating the suffix miniums. The time complexity is $$$O(\sum{n^2m})$$$, space complexity is $$$O(nm)$$$.
1580B - Mathematics Curriculum
idea: interlude
preparation: interlude
tutorial: CQXYM
Define the dp state $$$f_{l,s,d}$$$ as the number of the permutaion length of $$$l$$$ with exactly $$$d$$$ such numbers that all the subsegments containing them have exactly $$$s$$$ different maxima in total. We enumerate the position of the bigest number in the permutaion. We call the position is $$$a$$$. The numbers before $$$a$$$ and after $$$a$$$ are independent. Then we transform the statement $$$(l,s,d)$$$ to $$$(a-1,x,d+1)$$$ and $$$(l-a,y,d+1)$$$. We also have to distribute the numbers to two parts, so the dp transformation is:
$$$f_{l,s,d}=\sum_{a=1}^{l} \binom{l-1}{a-1} \sum_{x=0}^{s}f_{a-1,x,d+1}f_{l-a,s-x-[d=k],d+1}$$$
In addition, the answer of the problem is $$$f_{n,m,k}$$$. Actually, the dp proccess is just like a cartesian tree. The time complexity is $$$O(n^2m^2k)$$$, space complexity is $$$O(nmk)$$$. However, it's enough to pass the tests.
1580C - Train Maintenance
idea: interlude
preparation: interlude
Let's distinguish the trains according to $$$x_i + y_i$$$.
If $$$x_i + y_i > \sqrt{m}$$$, the total times of maintenance and running don't exceed $$$\frac{m}{\sqrt{m}}=\sqrt{m}$$$. So we can find every date that the train of model $$$i$$$ begin or end maintenance in $$$O(\sqrt{m})$$$, and we can maintain a differential sequence. We can add 1 to the beginning date and minus 1 to the end date, and the prefix sum of this sequence is the number of trains in maintenance.
If $$$x_i + y_i \le \sqrt{m}$$$, suppose the train of model $$$i$$$ is repaired at $$$s_i$$$ day. For a date $$$t$$$ that the train of model $$$i$$$ is in maintenance if and only if $$$(t-s_i) \ mod \ (x_i+y_i) \geq x_i$$$. Thus for each $$$a \le \sqrt{m}$$$, we can use an array of length $$$a$$$ to record the date of all trains that satisfy $$$x_i + y_i = a$$$ are in maintenance modulo $$$a$$$. And for one period of maintenance, the total days aren't exceed $$$\sqrt{m}$$$. So we can maintain $$$(t - s_i) \ mod \ (x_i + y_i)$$$ in $$$O(\sqrt{m})$$$.
Thus the intended time complexity is $$$O(m\sqrt{m})$$$ and the intended memory complexity is $$$O(n + m)$$$.
Tutorial by CQXYM
Finished reading the statement, you may have thought about this easy solution as followed. Maintain an array to count the trains in maintenance in each day. For add and remove operations, traverse the array and add the contribution to the array. The algorithm works in the time complexity of $$$O(nm)$$$. Besides, we can use the difference array to modify a segment in $$$O(1)$$$. However, we can optimize this solution. For the trains of $$$x+y>\sqrt m$$$, we can modify every period by brute force because the number of periods is less than $$$\sqrt m$$$. For the trains of $$$x+y \leqslant \sqrt m$$$, the number of the periods can be large. In this case, we set the blocks, each of them sizes $$$O(\sqrt m)$$$. We can merge the modifies which are completely included in the same block, with the same length of period and the same start position in the block. It's fine to use an array to record this. Number of segments are not completely included in the block is about $$$O(\sqrt m)$$$. The total complexity is $$$O(m\sqrt m)$$$.
1580D - Subsequence
idea: interlude
preparation: interlude
First we can change the way we calculate the value of a subsequence. We can easily see the value of a subsequence $$$a_{b_1},a_{b_2},\ldots ,a_{b_m}$$$ is also $$$\sum_{i = 1}^m \sum_{j = i + 1}^m a_{b_i} + a_{b_j} - 2 \times f(b_i, b_j)$$$, which is very similar to the distance of two node on a tree. Thus we can build the cartesian tree of the sequence, and set the weight of a edge between node $$$i$$$ and $$$j$$$ as $$$|a_i - a_j|$$$. Then we can see what we are going to calculate turns into follows : choosing $$$m$$$ nodes, maximize the total distance between every two nodes. Thus we can solve this task using dynamic programming with the time complexity $$$O(n^2)$$$.
Tutorial by CQXYM
From the statement, we'd calculate the sums like $$$a_i+a_j-Min_{k=i}^j a_k$$$. When we put this on a cartesian tree, it turns out to be $$$a_i+a_j-a_{LCA(i,j)}$$$. Set the weigth of the edge $$$x \rightarrow y$$$ as $$$a_y-a_x$$$, $$$a_i+a_j-a_{LCA(i,j)}$$$ equals to the distance between node $$$i,j$$$ on the tree. Define the dp state $$$f_{i,j}$$$ as the maxium answer in the subtree rooted at node $$$i$$$, and we choose $$$j$$$ of the nodes in the subtree. Enumerate how many nodes we choose in the subtree of left-son of node $$$i$$$, number of nodes of right-son, and whether node $$$i$$$ is chose. The contribution made by the edge is its weight times the number of nodes are chose. Since a pair of node will contribute time complexity only when we are calculating the dp state of their LCA, the total time complexity is $$$O(n^2)$$$.
1580E - Railway Construction
idea: interlude
preparation: interlude
tutorial: interlude
For convenience, we first define $$$dis[u]$$$ as the length of the shortest path between node 1 and node $$$u$$$ and "distance" of node $$$u$$$ as $$$dis[u]$$$, and call node $$$u$$$ is "deeper" than node $$$v$$$ if and only if $$$dis[u] > dis[v]$$$. Similarly, we call node $$$u$$$ is "lower" than node $$$v$$$ if and only if $$$dis[u] < dis[v]$$$. We will use $$$u$$$ -> $$$v$$$ to denote a a directed edge staring at node $$$u$$$ and ending at node $$$v$$$, and use $$$u$$$ --> $$$v$$$ to denote an arbitrary path staring at node $$$u$$$ and ending at node $$$v$$$. We call two paths "intersect" if and only if they pass through at least 1 same node.
First let's focus on several facts.
- Since all edges' weights are positive, and we have to make sure that the distance of every node does not change, for any node $$$u$$$, we can only add edges starting at a node whose distance is strictly less than $$$dis[u]$$$. Besides, we can always add edge 1 -> $$$u$$$, but we can never add edge $$$u$$$ -> 1.
- Since the distance of every node does not change and the train only pass through the shortest path, if an edge is not on the shortest path at first, however we add edges it won't be on any shortest path. Thus we can first calculate the shortest path and then remove all edges which are not on the shortest path. We can easily see that the new graph is a $$$DAG$$$ (Directed Acyclic Graph). And in this graph the topological order is also the ascending order of nodes' distances. In the following part of this tutorial, we will use the new graph instead of the original graph.
- After we add all edges, every node except node 1 must have at least 2 incoming edges.
Then let's prove a lemma: if every node except node 1 exactly has 2 incoming edges, the graph will meet the requirement.
We will use mathematical induction method to prove the lemma. For an arbitrary node $$$u$$$, we suppose that all nodes whose distance is less than $$$u$$$'s has met the requirement, and we only need to prove that node $$$u$$$ also meets the requirement. Suppose the start of the 2 incoming edges is separately $$$s$$$ and $$$t$$$.
First, if $$$s$$$ or $$$t$$$ is node 1, we can simply choose $$$1$$$ --> $$$u$$$ and $$$1$$$ --> $$$t$$$ -> $u$ as the two paths and obviously they don't intersect. Thus it meet the requirement.
Second, if $$$s$$$ and $$$t$$$ are not node 1. We choose an arbitrary path $$$1$$$ --> $$$s$$$ and call it path 0. According to our assumption, we can choose two different paths starting at node 1 and ending at node $t$, and the two paths don't intersect. We call them path 1 and path 2 separately.
If path 0 and path 1 (or path 2) doesn't intersect, then we can choose path 0 and path 1 to meet the requirement. Thus we only need to consider the situation that path 0 intersect with both path 1 and path 2.
In this case, we first find the lowest and deepest node where path 0 and path 1 or path 2 intersect, and call them $$$a$$$ and $$$b$$$ separately.
If the both are the intersect points of path 0 and path 1, like the case below, we can choose path (1 -> a -> (through path 1, i.e. blue path) b -> s) and path 2.
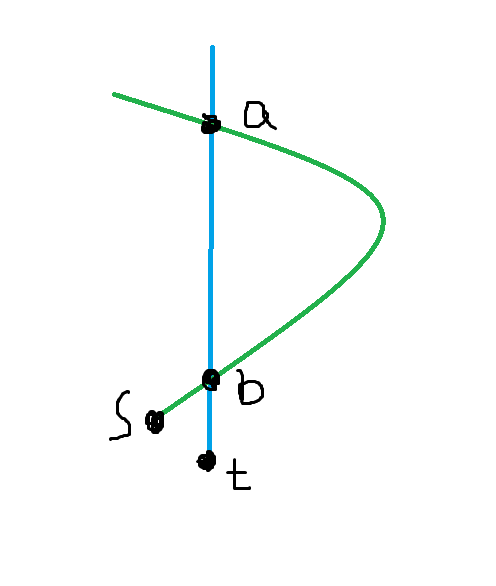
Otherwise, like the case below, we can choose path (1 -> a -> t) and path (1 -> b -> s).
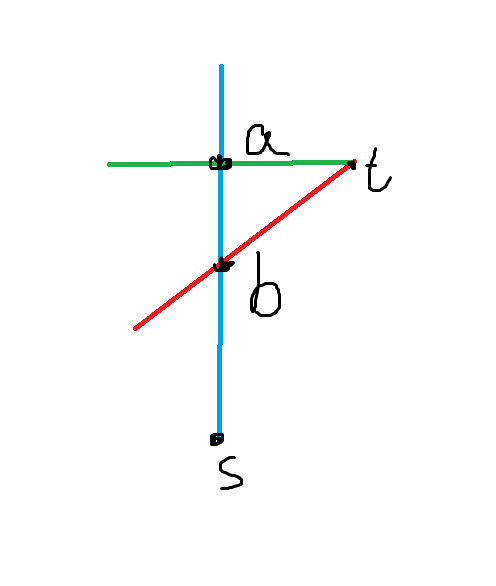
Both cases are meet the requirement.
Thus we've proved the lemma. So we only need to make sure that every node except node 1 has at least 2 incoming edges. Then we can get the following solution if $$$w$$$ is fixed:
For every node which has only 1 incoming edge, we record the start point of the incoming edge in an array. Then We scan all nodes in the ascending order of nodes' distances, and maintain the previous minima and second minima of $$$w$$$ in an array $$$val$$$, adding edges greedy. Note that we only need to maintain the index of $$$w$$$ instead of its real value. This solution consumes $$$O(n)$$$ to calculate for a fixed $$$w$$$, so the total complexity is $$$O(nq)$$$.
To accelerate the solution, let's try maintaining array $$$val$$$ while changing $$$w$$$. And we will apply all the changes in reverse order. That is, we only consider the case that $$$w$$$ is decreasing.
According to the value of $$$val$$$, we can separate the sequence into many subsegments, and we can use std::set to maintain those subsegments. For one change in $$$w_k$$$, it will affect a particular suffix of $$$val$$$, so we can first find the suffix. Then we consecutively change the array $$$val$$$ until $$$w_k$$$ is greater than current subsegment's second minima. Next we will prove that the solution works in $$$O((n+q)logn)$$$.
When we change a particular subsegment, we separate the operation into 3 types according to the relationship between $$$w_k$$$ and the subsegment's $$$val$$$.
- If $$$w_k$$$ is exactly the minima of the subsegment. This kind of operation may be done many times, but we will find that it won't change $$$val$$$ at all. So we can do them at a time using segment tree. Thus in one change we will only do it at most 1 time.
- If $$$w_k$$$ is the second minima of the subsegment. Note the fact that every subsegment must has different second minima, so this kind of operation will be also done at most once in one change.
- If $$$w_k$$$ is neither the minima nor the second minima of the subsegment. Note the fact that each time we do it, except the first time, will make the number of subsegments decrease by 1. Thus this kind of operation will be done no more than $$$n+q$$$ times.
Using std::set and segment tree, all of these operations could be done in $$$O(logn)$$$ at a time. Thus the total complexity is $$$O((n+q)logn)$$$.
In conclusion, we can solve this task in $$$O(mlogm + (n+q)logn)$$$.
1580F - Problems for Codeforces
idea: CQXYM
preparation: CQXYM
tutorial: CQXYM
If two numbers $$$a,b$$$ satisfying $$$a+b<m$$$, there can only be one number not less than $$$\lceil \frac{m}{2} \rceil$$$. Consider that cut the cycle to a sequence at the first position $$$p$$$ satisfying $$$\max(a_p,a_{p+1})<\lceil \frac{m}{2} \rceil$$$. When we minus all the numbers that are not less than $$$\lceil \frac{m}{2} \rceil$$$ by $$$\lceil \frac{m}{2} \rceil$$$, we can get a sub-problem. However, If $$$n$$$ is an even number, we may not find such a position $$$p$$$, but we can still get a sub-problem easily. For this problem on a sequence, we can divide the sequence into many segments, and each of them can not be cut by us anymore. There may be only $$$1$$$ segment, and the first, last element of the segment are not less than $$$\lceil \frac{m}{2} \rceil$$$. There may be many segments, the length of the first one and last one are even, and the rest of them are odd. To solve the problem, we define the GF A,B. A is the GF of the length of the segments are odd situation, and B is the even one. If $$$m$$$ is odd, the segment with only a number $$$[\frac{m}{2}]$$$ exists, and the GF of number of the sequence should be:
$$$B^2(\sum_{i=0} (A+x)^i)+A=\frac{B^2}{1-x-A}+A$$$
Otherwise, it is:
$$$B^2(\sum_{i=0} A^i)+A=\frac{B^2}{1-A}+A$$$.
To solve this problem, use NTT and polynomial inversion algorithm is just ok. Each time we transform a problem with limit $$$m$$$ to $$$\frac{m}{2}$$$, so the time complexity is $$$O(n \log n \log m)$$$.

