Hi!
I've recently found Spoj ToolKit. It's features:
- Random number, array, string, tree, graph generation.
- A big database of correct solutions to check if your output is correct for custom input.
Let's help this website by adding more correct solutions to its database.






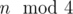 in a faster way.
in a faster way.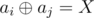 then
then 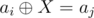 . Use trie.
. Use trie. is
is 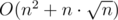 solution :O.
solution :O.
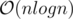 time (for all of the queries)?
time (for all of the queries)? .
. .
.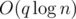 time (for
time (for