


Hi everyone!
On-site competitive programming competitions are rare and valuable events, and we all practice hard to have great competition. But I guess we are missing a point. One notable opportunity that exists in these kinds of events is getting to know other members of the competitive programming community, more than what we see in the scoreboards. The lunch club was a cool way of using this opportunity. (scott_wu, are we going to have the club this year? )
I remember the last day of IOI 2017. After everything was finished and the medals were given, I went back to the hotel and I saw an unexpected scene. I found there is this cool tradition in IOIs that in the last day contestants gather together, take pictures, and give out souvenirs. (FYI, I wasn't an IOI participant, I was in the host scientific committee.) I still have the souvenirs that I got from Japanese and Chinese contestants, and It encouraged me to search and get more familiar with their cool cultures.
So, in the remaining days before the trip to Portugal, I'm going to buy some souvenirs to give out in the world finals. I guess we can do this after dinner on the last day, in the lobby of the hotel. I'd be glad if you come and get it!
If you are interested, join the club and bring something from your country for everyone! Maybe this way, we start the tradition of bringing souvenirs to the world finals.
UPD: As stated here, the meeting is better to be in the farewell dinner hall instead of the hotel lobby. So we'll meet in Alfândega — West Ground Floor on Thursday. We will need to bring our souvenirs when leaving the hotel in the morning because we will go directly to the closing ceremony and celebration dinner from the contest. Please let your friends know the change so that no one misses the gathering.
UPD2: Don't forget your souvenirs tomorrow!
Good luck in the contest. :)






 .
.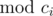 ) for each
) for each 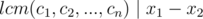
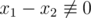 (
(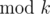 ). As a result:
). As a result: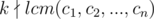
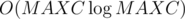 .
. 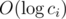 by moving from
by moving from 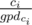 and adding
and adding 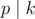 , see if there exists any coin
, see if there exists any coin 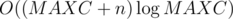 .
.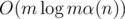 .
. solution for each query, which fits in time limit.
solution for each query, which fits in time limit.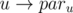 from this tree as the first edge in
from this tree as the first edge in 

 is
is 
 :(
:(