


Всем привет!
Осенью на физтехе проходили сборы по программированию Moscow International Workshop ACM ICPC. На них мне довелось прочесть лекцию по суффиксным структурам (на самом деле, были затронуты только суффиксное дерево и суффиксный автомат). В связи с этим я хотел бы предоставить вашему вниманию конспект лекции. Собственно, вот русская и английская версии. Приятного просмотра и счастливого Нового года :)
P.S. любая критика, предложения, пожелания и вопросы всячески приветствуются.
P. P. S. Я попытался достаточно подробно описать доказательство линейности работы, но, скорее всего, оно до сих пор тяжело воспринимается. Вы получите +100 единиц кармы, если разберётесь в нём и предложите более простой для понимания вариант :)
UPD: Спасибо Burunduk1 за помощь в форматировании кода :)
UPD2: См. также статью на Википедии по этой теме. Я являюсь основным автором текущей (29 октября 2021) версии статьи.






 в онлайне относительно приписывания символа в конец строки (т.е. ответ будет получен для каждого префикса). Также будет рассмотрена задача разбиения строки на
в онлайне относительно приписывания символа в конец строки (т.е. ответ будет получен для каждого префикса). Также будет рассмотрена задача разбиения строки на 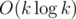 в оффлайне. Первый алгоритм с такой оценкой был получен Дэвидом Эппштейном в 1992 году сведением к fully dynamic minimum spanning tree problem, однако здесь речь пойдёт о более простом алгоритме, предложенном в 2012 году Сергеем
в оффлайне. Первый алгоритм с такой оценкой был получен Дэвидом Эппштейном в 1992 году сведением к fully dynamic minimum spanning tree problem, однако здесь речь пойдёт о более простом алгоритме, предложенном в 2012 году Сергеем 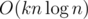 ? Если да, то как? Если нет, то почему?
? Если да, то как? Если нет, то почему? 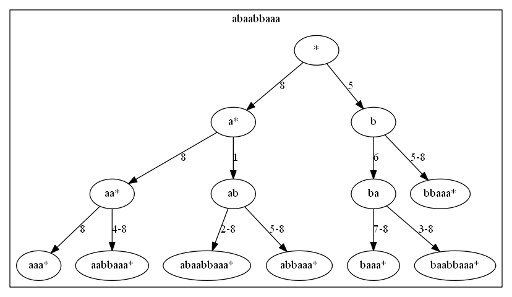
 времени и памяти.
времени и памяти.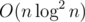 (возможно, при грамотной реализации можно и
(возможно, при грамотной реализации можно и  Пускай индекс элемента в массиве (назовём его для удобства
Пускай индекс элемента в массиве (назовём его для удобства 
