


664A - Complicated GCD
Author of the idea — GlebsHP
We examine two cases:
- a = b — the segment consists of a single number, hence the answer is a.
- a < b — we have gcd(a, a + 1, a + 2, ..., b) = gcd(gcd(a, a + 1), a + 2, ..., b) = gcd(1, a + 2, ..., b) = 1.
663A - Rebus
Author of the idea — gen
First we check whether any solution exists at all. For that purpose, we calculate the number of positive (the first one and any other with the + sign) and negative elements (with the - sign) in the sum. Let them be pos and neg, respectively. Then the minimum value of the sum that can be possibly obtained is equal to min = (1 · pos - n · neg), as each positive number can be 1, but all negative can be - n. Similarly, the maximum possible value is equal to max = (n · pos - 1 · neg). The solution therefore exists if and only if min ≤ n ≤ max.
Now suppose a solution exists. Let's insert the numbers into the sum one by one from left to right. Suppose that we have determined the numbers for some prefix of the expression with the sum of S. Let the sign of the current unknown be sgn ( + 1 or - 1) and there are some unknown numbers left to the right, excluding the examined unknown, among them pos_left positive and neg_left negative elements. Suppose that the current unknown number takes value x. How do we find out whether this leads to a solution? The answer is: in the same way we checked it in the beginning of the solution. Examine the smallest and the largest values of the total sum that we can get. These are equal to min_left = (S + sgn · x + pos_left - n · neg_left) and max_left = (S + sgn · x + n · pos_left - neg_left), respectively. Then we may set the current number to x, if min_left ≤ n ≤ max_left holds. To find the value of x, we can solve a system of inequalities, but it is easier simply to check all possible values from 1 to n.
BONUS Let k be the number of unknowns in the rebus. Prove that the complexity of the described solution (implementation shown below) is O(k2 + n), not O(k · n).
662D - International Olympiad
Author of the idea — Alex_2oo8
Consider the abbreviations that are given to the first Olympiads. The first 10 Olympiads (from year 1989 to year 1998) receive one-digit abbreviations (IAO'9, IAO'0, ..., IAO'8). The next 100 Olympiads (1999 - 2098) obtain two-digit abbreviations, because all one-digit abbreviations are already taken, but the last two digits of 100 consecutive integers are pairwise different. Similarly, the next 1000 Olympiads get three-digit abbreviations and so on.
Now examine the inversed problem (extract the year from an abbreviation). Let the abbreviation have k digits, then we know that all Olympiads with abbreviations of lengths (k - 1), (k - 2), ..., 1 have passed before this one. The number of such Olympiads is 10k - 1 + 10k - 2 + ... + 101 = F and the current Olympiad was one of the 10k of the following. Therefore this Olympiad was held in years between (1989 + F) and (1989 + F + 10k - 1). As this segment consists of exactly 10k consecutive natural numbers, it contains a single number with a k-digit suffix that matches the current abbreviation. It is also the corresponding year.
662B - Graph Coloring
Author of the problem — gen
Examine the two choices for the final color separately, and pick the best option afterwards. Now suppose we want to color the edges red.
Each vertex should be recolored at most once, since choosing a vertex two times changes nothing (even if the moves are not consecutive). Thus we need to split the vertices into two sets S and T, the vertices that are recolored and the vertices that are not affected, respectively. Let u and v be two vertices connected by a red edge. Then for the color to remain red, both u and v should belong to the same set (either S or T). On the other hand, if u and v are connected by a blue edge, then exactly one of the vertices should be recolored. In that case u and v should belong to different sets (one to S and the other to T).
This problem reduces to 0-1 graph coloring, which can be solved by either DFS or BFS. As the graph may be disconnected, we need to process the components separately. If any component does not have a 0-1 coloring, there is no solution. Otherwise we need to add the smallest of the two partite sets of the 0-1 coloring of this component to S, as we require S to be of minimum size.
662A - Gambling Nim
Author of the idea — GlebsHP
It is known that the first player loses if and only if the xor-sum of all numbers is 0. Therefore the problem essentially asks to calculate the number of ways to arrange the cards in such a fashion that the xor-sum of the numbers on the upper sides of the cards is equal to zero.
Let 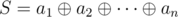 and
and 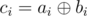 . Suppose that the cards with indices j1, j2, ..., jk are faced with numbers of type b and all the others with numbers of type a. Then the xor-sum of this arrangement is equal to
. Suppose that the cards with indices j1, j2, ..., jk are faced with numbers of type b and all the others with numbers of type a. Then the xor-sum of this arrangement is equal to 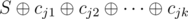 , that is,
, that is, 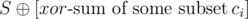 . Hence we want to find the number of subsets ci with xor-sum of S.
. Hence we want to find the number of subsets ci with xor-sum of S.
Note that we can replace c1 with  , as applying c1 is the same as applying
, as applying c1 is the same as applying 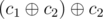 . Thus we can freely replace {c1, c2} with and c2 with
. Thus we can freely replace {c1, c2} with and c2 with 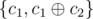 . This means that we can apply the following procedure to simplify the set of ci:
. This means that we can apply the following procedure to simplify the set of ci:
- Pick cf with the most significant bit set to one
- Replace each ci with the bit in that position set to one to

- Remove cf from the set
- Repeat steps 1-5 with the remaining set
- Add cf back to the set
After this procedure we get a set that contains k zeros and n - k numbers with the property that the positions of the most significant bit set to one strictly decrease. How do we check now whether it is possible to obtain a subset with xor-sum S? As we have at most one number with a one in the most significant bit, then it tells us whether we should include that number in the subset or not. Similarly we apply the same argument for all other bits. If we don't obtain a subset with the xor-sum equal to S, then there is no such subset at all. If we do get a subset with xor-sum S, then the total number of such subsets is equal to 2k, as for each of the n - k non-zero numbers we already know whether it must be include in such a subset or not, but any subset of k zeros doesn't change the xor-sum. In this case the probability of the second player winning the game is equal to 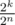 , so the first player wins with probability
, so the first player wins with probability 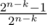 .
.
662C - Binary Table
Author of the idea — Alex_2oo8
First let's examine a slow solution that works in O(2n · m). Since each row can be either inverted or not, the set of options of how we can invert the rows may be encoded in a bitmask of length n, an integer from 0 to (2n - 1), where the i-th bit is equal to 1 if and only if we invert the i-th row. Each column also represents a bitmask of length n (the bits correspond to the values of that row in each of the n rows). Let the bitmask of the i-th column be coli, and the bitmask of the inverted rows be mask. After inverting the rows the i-th column will become 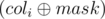 . Suppose that contains
. Suppose that contains 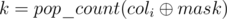 ones. Then we can obtain either k or (n - k) ones in this column, depending on whether we invert the i-th column itself. It follows that for a fixed bitmask mask the minimum possible number of ones that can be obtained is equal to
ones. Then we can obtain either k or (n - k) ones in this column, depending on whether we invert the i-th column itself. It follows that for a fixed bitmask mask the minimum possible number of ones that can be obtained is equal to 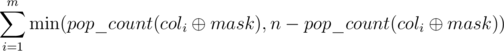 .
.
Now we want to calculate this sum faster than O(m). Note that we are not interested in the value of the mask itself, but only in the number of ones it contains (from 0 to n). Therefore we may group the columns by the value of 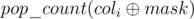 . Let dp[k][mask] be the number of such i that
. Let dp[k][mask] be the number of such i that 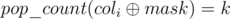 , then for a fixed bitmask mask we can calculate the sum in O(n) —
, then for a fixed bitmask mask we can calculate the sum in O(n) — 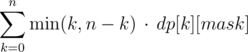 .
.
What remains is to calculate the value of dp[k][mask] in a quick way. As the name suggests, we can use dynamic programming for this purpose. The value of dp[0][mask] can be found in O(m) for all bitmasks mask: each column coli increases dp[0][coli] by 1. For k > 0, coli and mask differ in exactly k bits. Suppose mask and coli differ in position p. Then coli and 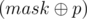 differ in exactly (k - 1) bits. The number of such columns is equal to
differ in exactly (k - 1) bits. The number of such columns is equal to 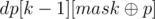 , except we counted in also the number of columns coli that differ with in bit p (thus, mask and coli have the same value in bit p). Thus we need to subtract dp[k - 2][mask], but again, except the columns among these that differ with mask in bit p. Let
, except we counted in also the number of columns coli that differ with in bit p (thus, mask and coli have the same value in bit p). Thus we need to subtract dp[k - 2][mask], but again, except the columns among these that differ with mask in bit p. Let 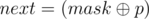 ; by expanding this inclusion-exclusion type argument, we get that the number of masks we are interested in can be expressed as dp[k - 1][next] - dp[k - 2][mask] + dp[k - 3][next] - dp[k - 4][mask] + dp[k - 5][next] - .... By summing all these expressions for each bit p from 0 to n, we get dp[k][mask] · k, since each column is counted in k times (for each of the bits p where the column differs from mask).
; by expanding this inclusion-exclusion type argument, we get that the number of masks we are interested in can be expressed as dp[k - 1][next] - dp[k - 2][mask] + dp[k - 3][next] - dp[k - 4][mask] + dp[k - 5][next] - .... By summing all these expressions for each bit p from 0 to n, we get dp[k][mask] · k, since each column is counted in k times (for each of the bits p where the column differs from mask).
Therefore, we are now able to count the values of dp[k][mask] in time O(2n · n3) using the following recurrence:
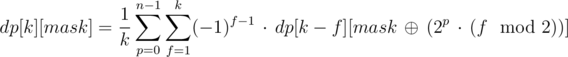
This is still a tad slow, but we can speed it up to O(2n · n2), for example, in a following fashion:
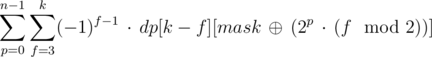
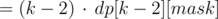
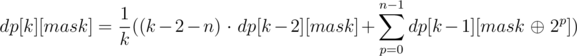
BONUS Are you able to come up with an even faster solution?
662E - To Hack or not to Hack
Author of the idea — Alex_2oo8
Observation number one — as you are the only participant who is able to hack, the total score of any other participant cannot exceed 9000 (3 problems for 3000 points). Hence hacking at least 90 solutions automatically guarantees the first place (the hacks alone increase the score by 9000 points).
Now we are left with the problem where the number of hacks we make is at most 90. We can try each of the 63 possible score assignments for the problems in the end of the round. As we know the final score for each problem, we can calculate the maximum number of hacks we are allowed to make so the problem gets the assigned score. This is also the exact amount of hacks we will make in that problem. As we know the number of hacks we will make, we can calculate our final total score. Now there are at most 90 participants who we can possibly hack. We are interested only in those who are on top of us. By hacking we want to make their final score less than that of us. This problem can by solved by means of dynamic programming:
dp[p][i][j][k] — the maximum number of participants among the top p, whom we can push below us by hacking first problem i times, second problem j times and third problem k times.
The recurrence: we pick a subset of solutions of the current participant that we will hack, and if after these hacks we will push him below us, we update the corresponding dp state. For example, if it is enough to hack the first and the third problems, then dp[p + 1][i + 1][j][k + 1] = max(dp[p + 1][i + 1][j][k + 1], dp[p][i][j][k] + 1)
BONUS Can you solve this problem if each hack gives only 10 points, not 100?






The new feature for showing code is really awesome :D
In problem To Hack or not to Hack, won't the official approach be too slow? since If I understand correctly, the dp part take O(90^4*2^3), and the enumeration part takes O(6^3), which, when multiplied, is very large
upd: after some rethinking the dp part actually takes O(90*(triple(a,b,c):(a+b+c<90))*8), which the number of triple is around 125580, so it still looks pretty large.
More or less formal approximation of the complexity: 90 hacks is an actual worst case only for scoring 3000 - 3000 - 3000, so, if we have fixed the scoring to be, say, 1000 - 500 - 1500 and we are still allowed to make at least 30 hacks overall, the dynamic programming won't take any time at all, as we are only processing participants that are initially above us, but with 30 hacks and considered scoring we are already taking the first place. So, for scoring 1000 - 500 - 1500 we can approximate the maximal number of hacks on each problem as 10 - 5 - 15 respectively. Thus the total complexity can be approximated as 30 · (5 + 10 + 15 + 20 + 25 + 30)3 · 7 = 243'101'250, in worst case we will have 30 participants with all 3 problems hackable (this way we have an additional factor of 7 for subset of problems that we will hack).
In practice, it is impossible to design a testcase, where we will have exactly the maximal number of hacks allowed for all of 63 potential scorings. I have just tried some nearly worst cases and the maximal number of DP transitions (taking the solution from the editorial) I was able to achieve is 104'533'689 on the following test case:
The reference solution takes approximately 200 ms on this test case.
How to be you
IS There any other approach for problem Rebus ? if you someone know he would help me a lot?
Correct me if I'm wrong. I solved this problem by using binary search. First, at the left side, let's say the number of positive integers is A and that of negative B. Then we can now say that the sum of positive integers(counted A) equals n+abs(negative intergers). All numbers should be -n~n(except 0). So the right side of my form should be in range [n+B*1 ~ n+B*n]. If we suppose one value V in that range, it can be split into A segments. Let's give value (int)V/A to the first of left side. After then, we have only value V-(int)V/A and (A-1) segments. By trying them, we can now figure out if it is possible. First condition : if V/A is larger than n, =>No Second condition : value returned 0 but still have segments => NO Third condition : Have no segments but sill have V > 0 =>No By this, we can adjust V.
But my question is, I set V just like n+b, n+b*2, n+b*3, ...n+b*n but accepted. Can anyone prove or disprove it's ok or not?
Can Someone Explain 662A - Gambling Nim.
Not able to get the editorial
Hi !
for the Bonus of problem 'Rubus' I think it can be proved that the code given in the solution works in O(N + K) and not O(n + k^2)
correct me if I am wrong
thanks !
I notice that in the tags for 'E. Binary Table', there are 'divide and conquer', and 'fft', would somebody please provide some explanations on that? Thanks in advance.
In fact, it can be solved with an algorithm similar to FFT. It's FWHT — Fast Walsh-Hadamard Transform — an algorithm to calculate the XOR convolution: c[x] = Sum[y = 0 .. 2^n-1] a[y] * b[x XOR y], in O(2^n * n) time.
Let a[x] be the number of x appeared in the columns, b[x] = min(popcount(x), n-popcount(x)), then the answer for mask is ans[mask] = Sum[x = 0 to 2^n-1] a[x] * b[x XOR mask], which is exactly the XOR convolution and can be calculated with FWHT in O(2^n * n) time.
Perhaps the one who added the tag couldn't find this algorithm and chose a similar one.
Thanks for that!
can someone please explain about 0-1 graph coloring and some resources to learn it. This topic is quite new to me. Thanks in advance :D
A 0-1 coloring of a graph is a way to color its vertices such that for every edge, the vertices connected by this edge have different colors. You can find if there is a 0-1 coloring of a connected undirected graph using DFS or BFS. Just start from any vertex and say its color is 0, for example. For every vertex adjacent to it that hasn't been visited yet, call dfs for it, and color it the opposite color of the vertex that's being processed now. If after this, there's still an edge that has both endpoint vertices colored the same way, then there's no 0-1 coloring for this graph. Here's how i code it: https://pastebin.com/DVuvH2Rc
Can someone please explain "...except we counted in also the number of columns coli that differ with in bit $$$p$$$ (thus, $$$mask$$$ and $$$col_i$$$ have the same value in bit $$$p$$$). Thus we need to subtract $$$dp[k - 2][mask]$$$". I don't understand why we need to subtract $$$dp[k-2][mask]$$$.