


I have been trying to solve this question with MO's algorithm. but My solution was getting TLE. Please somebody share an approach, if it is possible to solve with MO's algorithm . Link to problem : http://codeforces.net/contest/588/problem/E
→ Pay attention
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3856 |
| 2 | jiangly | 3747 |
| 3 | orzdevinwang | 3706 |
| 4 | jqdai0815 | 3682 |
| 5 | ksun48 | 3591 |
| 6 | gamegame | 3477 |
| 7 | Benq | 3468 |
| 8 | Radewoosh | 3462 |
| 9 | ecnerwala | 3451 |
| 10 | heuristica | 3431 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | -is-this-fft- | 162 |
| 3 | Dominater069 | 160 |
| 4 | Um_nik | 158 |
| 5 | atcoder_official | 157 |
| 6 | Qingyu | 156 |
| 7 | djm03178 | 151 |
| 7 | adamant | 151 |
| 9 | luogu_official | 150 |
| 10 | awoo | 147 |
→ Find user
→ Recent actions





Codeforces (c) Copyright 2010-2025 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Feb/23/2025 01:47:04 (j2).
Desktop version, switch to mobile version.
Supported by

Auto comment: topic has been updated by drexdelta1 (previous revision, new revision, compare).
Keeping the set of people on the current path in a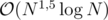 time complexity, which is unlikely to pass. In a set it is
time complexity, which is unlikely to pass. In a set it is 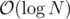 for inserting, deleting and finding the minimal a elements. However you insert and delete more often than you find the minimal elements.
for inserting, deleting and finding the minimal a elements. However you insert and delete more often than you find the minimal elements.
set<int>or similar structure will have aThere exists a data structure which lets you insert and delete elements in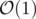 , while taking
, while taking 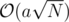 to find the minimal elements. For this, divide the range of legal values into
to find the minimal elements. For this, divide the range of legal values into  equal blocks and for each block keep a hash table containing all the added elements in that block. To insert or delete, simply access the relevant hash table, to find minimal, iterate through all possible elements while skipping the ranges where the hash table is empty. Using this, the complexity is
equal blocks and for each block keep a hash table containing all the added elements in that block. To insert or delete, simply access the relevant hash table, to find minimal, iterate through all possible elements while skipping the ranges where the hash table is empty. Using this, the complexity is 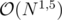
It is also worth noting that in the case of this problem, after you flatten the tree into an array, instead of dividing into blocks of cities, you should divide into blocks of
cities, you should divide into blocks of  people, otherwise Mo's algorithm won't optimize as intended.
people, otherwise Mo's algorithm won't optimize as intended.
This is still quite slow, the constant is large and hash-tables only support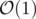 on average, not every time. I would prefer to use a method that uses
on average, not every time. I would prefer to use a method that uses 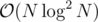 time. Centroid decomposition works really well here, HLD is not bad either.
time. Centroid decomposition works really well here, HLD is not bad either.
Hi, sorry for late reply.
I learnt something new, that you mentioned in second paragrah, and third paragraph. Thank you for your reply.
I will try it with centroid decomposition.