


The next round is at 14:00 UTC today
Top20 advances to the on-site round in Dublin
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3856 |
| 2 | jiangly | 3747 |
| 3 | orzdevinwang | 3706 |
| 4 | jqdai0815 | 3682 |
| 5 | ksun48 | 3591 |
| 6 | gamegame | 3477 |
| 7 | Benq | 3468 |
| 8 | Radewoosh | 3462 |
| 9 | ecnerwala | 3451 |
| 10 | heuristica | 3431 |
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | -is-this-fft- | 162 |
| 3 | Dominater069 | 160 |
| 4 | Um_nik | 158 |
| 5 | atcoder_official | 157 |
| 6 | Qingyu | 155 |
| 7 | djm03178 | 151 |
| 7 | adamant | 151 |
| 9 | luogu_official | 150 |
| 10 | awoo | 147 |
The next round is at 14:00 UTC today
Top20 advances to the on-site round in Dublin






Offering a challenge to everyone: solve problem A.
Tests in small testset for problem C are weak. My solution that didn't check that base is greater than any of appearing digits successfully passed them. Luckily, I managed to find that issue and resubmit my solution, though I moved from 10th place to 20+ after doing that.
Example: case 04 + 05 = 16, my original solution would output 3, but the answer is
Problem E (the nanobots one) is beautiful. UPD: sorry, mentioned wrong letter here. D is also nice, but not that nice as E :)
They're not weak enough to allow my wrong solutions to pass. It was the hardest problem of this contest for me... although I may have been better off not trying to be deterministic.
Isn't E just similar to gold from previous finals, it took me just 20 minutes to edit fhlasek's submission from last finals.
It's nice to hear that my solution was useful and easy to edit :-) Unfortunately, I didn't notice a similar approach may be used and implemented basically the same idea from scratch.
I could have been on 19th position if not for this :( Why DCJ organizers would be so cruel?
So it was in the large cases but not the small ones? A similar thing happened in 2015, where a very simple case wasn't in small or large, see http://codeforces.net/blog/entry/18561?#comment-235542
Huh, that's cruel :o. In my first submission I also got this bug, then found that I do not check exactly that condition and still got WA, because I got another sublte bug. I got lucky I had done that second bug, otherwise I wouldn't have noted that I do not check that digits < base xd.
I wonder what's the point of 10-minute timeout for resubmitting large solutions. Do they actually start being tested when there are resources available?
Does anyone have a deterministic (i.e. not hashing) solution for C?
Edit: Sorry, I meant D
Yes, two ranges a and b in two different nodes have one or two differences if and only if we don't have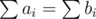 and
and 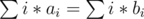 .
.
Yeah, but you shouldn't be doing this modulo 264.
Apparently, my polynomial hash modulo 264 passed.
It is hard to counter every possible bad attempt at hashing.
Why wouldn't it? (I mean if you choose multiplier randomly at least)
Is http://codeforces.net/blog/entry/4898 relevant?
I don't think so(or not directly) because you have at most two nonzero elements in this problem.
(259, 0, 0, ...) (0-th is nonzero) and (0, 0, ..., 0, 259, 0, 0, ...) (32th is nonzero).
Indeed, that seems to fail my solution.
Didn't think about the fact that big range allows to fail everything such easily
Indeed. I lost 20minutes and 1 penalty because my code to transmit 128bit integers didn't work on the google servers though, and my submission using 64bits integers was accepted...
Yes.
Let's just focus on the subproblem "test if this long number is 0 in base B". Split it into intervals, convert the number in it to the form where all digits except maybe the most significant one are in [0, B). That most significant digit is the "left carry" and nodes are going to gradually send carry values to each other. Compute the number which it must receive from its right neighbour in order to send exactly that left carry (or, if impossible, the number which results in sending left carry + 1); call this number "right carry".
More specifically: if we had L consecutive digits D[1..L] initially, we make a number with L + 1 digits D[0..L]; the most significant is D[0]. Now compute D[1..L] modulo B2 = x. If we didn't need to use the modulo (all digits D[0..L - 2] are zero), then the left carry is D[0] and right carry is - x. Otherwise, all digits D[0..L - 2] must be B - 1 (or the number can't be 0 in B); the left carry is D[0] + 1 and right carry is B2 - x.
When this interval receives c from the node to its right, it's the same as receiving c - cr with D[1..L] = 0; the actual carry is (c - cr) / BL + cr (if c - cr isn't divisible by BL, the number again can't be 0 in B) and we can send it to the node to its left. In the end, we have to check if the last carry is 0 and if neither node reported fail.
Compute both the left and right carries, then send the actual carries (which depend on each other but that's okay, they can be recomputed in O(1) now) and check if everything is okay.
UPD: To clarify, the first problem is B.
That's the price we have to pay because DCJ always names testrun as A xD
I wonder why they don't name testrun the last problem, it's strange to solve problems named
B..E, and is very inconvenient to discuss the problems afterwards.Nanobots was easiest problem for me today xD. Even flags took me longer and half of time I needed to solve nanobots was to note that experiment returns T or N and not 1 or 0 xdd.
I find my idea pretty neat, this was my shortest code today, so here it is:
For simplicity assume that #nodes==100. We divide range [1, 1e12] into 1e7 intervals of length 1e5. I divide these intervals evenly to nodes in random way. Every node counts result in all his intervals. Computing result within one interval takes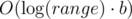 where b is number of nanobots there, simple binary search.
where b is number of nanobots there, simple binary search.
EDIT: It passed ^^
Well, because this question was almost similar to gold from last finals. Your idea is an exact copy of fhlasek's solution of gold :)
I don't know that problem ;p. However I am a bit afraid that my solution will get TLE :<. I will have to wait for results. EDIT: I am less afraid of TLE because I realized that usleep(1) takes on average 55microsecs, so doing it many times is not a good idea to check for TLE ;p (as I did in testrun)
I learned by reading correct submissions that it was enough to divide interval into 100 even pieces without any randomization.
OMG this is some poor joke... My friend noted it in almost same moment as you. That's an obvious solution that obviously TLEs --__--. Why is it so hard to create tests against first wrong solution that comes to mind?
Yep, I confirm this ;_;
Any usernames, please? I tried opening the ones submitted late and didn't find anything like that. I've found one solution splitting the interval into 100 pieces, but it's limiting the number of binary search runs and re-distributing remaining work, which is perfectly fine.
The reason I doubt it is because I have exactly the same "solution" submitted in the last minute on the off chance the tests are crap and it obviously TLE'd. On small doing the work on 10 nodes instead of 1 decreased the time from 1012ms to 998ms, which leads me to believe that they are handling this "solution" properly.
In other words, it seems to be the solution described in the last paragraph of the analysis.
No, he isn't re-distributing work, he is just splitting into 100 intervals. Also while checking top20 solutions I've found one which gives WA and another which gives MsgLE... Some rejudge maybe? XD
long long GetRange() { return 1000000000000LL; }
long long GetNumNanobots() { return 1000*10000; }
char Experiment(long long size, long long speed) { if ((size/100)+(speed/100000)<=(1000*10000)) return 'T'; return 'E'; }
He who? eduardische found johnchen902, who does at most
5 * (n / nodes + 1)iterations before reporting to the master node and redistributing the remaining search space.Just to check, is 998981514 the correct answer?
Yes, it is.
My solution gives 998981415, please tell me that's a typo :(
My slow solution on a single node also gives me 998981514 on this test case.
Sadly no, I've copypasted my answer.
Another tough case would be this:
Most people seem to handle this within the (enormous) TL, but I didn't make the functions purposedly slow.
I've also noticed that tourist's code exceeds total message size limit both on your and my cases. Might be a local bug with my environment though.
Well, my solution always sends at most 4*MAX 8-bit integers (plus a hundred 4-bit ones). In my submission, MAX = 240000, so I expect to send at most 7,68 MB.
In my local environment it does get "message size limit exceeded", though. It works with MAX = 230000, so I suspect that the communication system also sends a byte corresponding to the type of each variable — can someone confirm that? (I haven't read the rules :))
Nevertheless, my submission passed the system test, so maybe there's a difference between local and testing environments.
I’ve just dug into the source code of the local testing tool, and it does indeed appear that it sends a byte corresponding to the type of each field. It then verifies them on the other end and dies with a “Type mismatch between read and requested types” message if you try to read a wrong type.
This can be disabled by changing the value of the macro
DEBUGto 0 in libraries/message_internal.c and rebuilding the tool (or possibly just recompiling message_internal.o; it seems the object files are not linked together, at least in the macOS build that I have at hand). Judging by the macro name, I hope this is disabled in the actual contest, but I don’t think I’ve seen this explicitly mentioned anywhere.Hey, your test case is invalid, experiment returns 'T' for points (1, 1012) - (99, 1012). That explains W4yneb0t's answer — the difference is exactly 99.
Woooo, tourist saves the day by rebutting false accusations against himself and other innocent people, sorry for questioning your power ;)
adsz is doing it in the most naive way. His code is easily hacked by test posted by Radewoosh if we assume that each call takes 0.2s then his code works for 147s. In fact it runs in 5s, but it is because that particular function is very simple, so it is very fast, but you got the point.
I see. Then I'm at loss why my attempt at doing exactly that TLE'd: https://pastebin.com/R3uH7qrL. Any ideas? This passes the small, so I was hoping it's not just a bug.
Also, the test that Radewoosh mentioned isn't failing this type of solutions, since the bots are distributed evenly [UPD: Disregard this paragraph].
The download link for my E-large leads to my old solution (with broken constants). Maybe that could explain things?
Ah, that would explain everything perfectly. adsz also has one wrong answer. Seems like DCJ and the scoreboard does not get along with each other...
That's really strange, however actually, both solutions mentioned by Radewoosh were submitted only once on large. SizeOfMsgLE is tourist's (it seems that even when his codes are not correct then tests are adjusted accordingly to make it work ;p) and WA is W4yneb0t's. However maybe adsz submitted faster solution, he resubmitted it once.
I was more concerned about naive split not TL'ing. WA and SizeOfMsgLe is the usual "got lucky with the tests", so it's all fair.
I think that adsz carefully adjusted bounds of binary search to be as tight as possible. Are you also doing this?
And bots in Radewoosh's test are distributed not really evenly. They all fall into first interval if I'm not mistaken. Nevertheless, this test caused adsz code to make 737253930 calls on first adsz's node (~147s if one call is 0.2micros).
True, I haven't realized that. Sorry.
But I think simonlindholm has shed some light on the issue -- it seems that the scoreboard lets you download the first submitted solution and not the one that actually got accepted.
Nope, for small it seems to be the last one.
Well, it should pass for small. The scenario of submitting that for both small and large, and then improving the large isn't uncommon.
Results! Results!
UPD Editorial is up as well.
Meh, better 57th than 99th, but if I focused on E instead of C, I may have been in the finals.