


Let's discuss problems.
How to solve the geography problem?
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3856 |
| 2 | jiangly | 3747 |
| 3 | orzdevinwang | 3706 |
| 4 | jqdai0815 | 3682 |
| 5 | ksun48 | 3591 |
| 6 | gamegame | 3477 |
| 7 | Benq | 3468 |
| 8 | Radewoosh | 3462 |
| 9 | ecnerwala | 3451 |
| 10 | heuristica | 3431 |
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | -is-this-fft- | 162 |
| 3 | Dominater069 | 160 |
| 4 | Um_nik | 158 |
| 5 | atcoder_official | 157 |
| 6 | Qingyu | 155 |
| 7 | djm03178 | 151 |
| 7 | adamant | 151 |
| 9 | luogu_official | 150 |
| 10 | awoo | 147 |
Let's discuss problems.
How to solve the geography problem?







How to solve problem 2, 11?
The last problem: if after 6 hours the rocket is higher than the eclyptic, send it then; else the rocket crosses eclyptics, and that moment can be found with binary search; to find the position after t seconds, rotate point (0,-cos(phi),sin(phi)) by t/day_length*2pi around z-axis, then rotate it by -alpha around y-axis, and z-coordinate will be oriented distance to the eclyptic
Problem 11. Trigonometry. Find ratio between A1-L and A2-L (tangets). Then calculate arcsine.
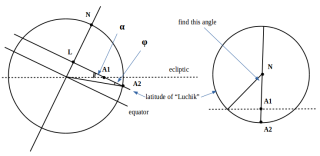
How to solve 2, 6 and 7?
2) Just determine time when item starts decoding and time when it's leaving the buffer than you get segments [enters_buffer, exits_buffer]. After just found point in time where maximum segments intersects. How to find this "enters_buffer": iterate from the end to begin and keep time when current item enters buffer, when iterating just update this smth like enters_buffer = min(enters_buffer, i * d); enters_buffer -= time_of_decoding[i]. There is a case when we have "IBBI" we know that 3 must be decoded before 1 so in our loop we skip 3 and update "enters_buffer" after iterating 1. So how to find "exits_buffer": for every item u iterate for each item v where v depends of u and choose maximum of enters_buffer[v] + time_of_decoding[v]
6) First of all, parse all input and calculate number of fields which take 1, 2, 4 and 8 bytes.
For minimal size we can order fields in non-increasing order and then add padding so that the total size is divided by max-size field.
Maximal and average sizes can be found using dynamic programming. Let's consider dp[r][c1][c2][c4][c8] be avg/max size of current structure where r is current size mod 8 and cX -- number of remaining fields with size X. When calculating average we also maintaining probability to get to each state. Transitions are done by inserting fields of all possible sizes. Then, for maximum we need to find max for all r among dp[r][0][0][0][0] and average equals sum of all dp[r][0][0][0][0] + probability[r] * padding(r) where padding(r) -- is padding we need to add to the resulting structure having remainder r.
The dynamics can be optimized by using only two layers
But i thought that numbers can be very big when we calculating avg so we can have loss of precision. Why they are remaining small?
As long as we have only 100 fields, maximal total size is 800 and average is less or equals to it
Yes, but probability equals to x over y, I thought that y can be very large, and x very small
I don't have ever seen single interesting problem, which is related to computer architecture with long description of buffer or memory, and I think this time is no exception...
I don't have ever seen single interesting problem with long description, and I think this time is no exception...
How to solve 3?
Kuhn or flows. With one of them it’s an easy task
Discard all packages that has at least one version that doesn't make conflict with any other package.
Now you are left with some packages where all versions make conflict with some other package. You want to choose exactly one version from each package, such that you also choose no more that 1 version from a conflict set. That is exactly like finding a matching, where all left nodes are included.
So, for this part, make a bipartite graph, with left nodes representing packages, and right nodes representing conflict sets. Add and edge between X and Y, if package X is in conflict set Y. Then answer is Yes, iff max bipartite matching = number of packages.
Solution can be constructed by looking at matched edges, and taking a version that is in both package and conflict set.
1.At first, check if there are any versions, which are not included in any conflict. Update answer for those programms.
2.Then, make a bipartite graph with conflicts in the left part and programms(which you don't have answers yet) in the right(and write a version on the every edge for output). Find maximum matching in that graph. That's it.
Greedy algorithm with random.
How to solve 9?
for each i = 0, 1, ..., n / s memorize the segments that are near point i * s, to answer the query with point x look at these ssegments at x / s - 1, x / s and x / s + 1; i took s as 4
Actually I only make all the coordinate 1E6 times larger and use a Segment Tree and Pass the problem. So I am wondering what's the official solution idea, Since my solution has nothing to do with the randomability.
Hmm, interesting. What kind of Segment Tree did you use? Don't you need to squeeze coordinates before?
My Segment Tree's range is [-1E11,2E11]. You don't have to squeeze coordinates if you maintain the Segment Tree by the way that only generates necessary nodes.
Well... The canonical solution is to build a segment tree with standard segment-nodes [k;k + 2s) for 2s|k. For each input interval, first find the best matching level s, then save its index into one or two segment-nodes which it intersects in this level. For a point query, go through all the nodes containing the point, and check all the intervals in it. This gives O(N) space in worst case and average O(NlogN) time with the provided distribution.
The much simpler solution is the one described by polingy below, which needs O(NlogN) time and space on average.
Of course, all sorts of other segment trees work as well.
We solved it with "naive" algorithm.
For every interval, [L, R] add it to vector for indices , to answer point query x, look at the vector corresp. to
, to answer point query x, look at the vector corresp. to  and just check how many intervals x lies inside.
and just check how many intervals x lies inside.
It's not hard to show that expected runtime is ; I don't know how to show that it's quick with high probability.
; I don't know how to show that it's quick with high probability.
it is quick because the average length of any interval is 4
It was said in the statement that radius of a segment R is generated with this — . So expected value of R is —
. So expected value of R is —
So, sum of lengths of segments is ~ .
.
We solved it with "interval tree"
Can also be solved with Binary Search Tree. Notice that number of segments that contains X = total number of segments — (number of segments that has right side < X + number of segments that has left side > X). So we can use two BSTs, one for storing left sides another for right, and keep sub-tree sum for the ids and size of sub-trees in each node. Since the data is random, so we don't need BBST like Splay-Tree / Treap, normal BST is enough.
Does anyone WA on 8th testcase of problem 7?
And I am also wondering is this Gp of Eurasia or Gp of Siberia? Quite comfusing.
I could pass the 8th test only by rewring computation from floating numbers to integers. But unfortunetaly, couldnt have time to squeze in TL.
About testcases in 4:
Store the sets for each component with indexes of bad irredeemable connection. When you need to merge it, first check from smaller set that there is no intersection. Then add small set to biggest. This solution should got TL, but during checking if we break inside the loop, when we found intersection got to AC.
But it is easy constract test case where it should have O(n^2) comparison. Isnt it?
I thought key idea would be dont compare two components more than once. But to get AC it is not needed. Is it bad testcases?
You meant Ω(n2), didn’t you?
How to solve 4?
use dsu, but while unioning sets, append one with lesser sets of conflict vertices to one with bigger; after unioning sets, if you appended B to A, then for each conflict vertex in B's set change B to A in that set
I have two solutions of problem F that differ only in the following lines:
Solution 1:
Solution 2:
The first solution gets OK while the second fails on test 1. Can someone explain that?
How to solve 10?
Dijkstra on hex graph: build graph -> don't forget to add reverse edges for rivers -> run Dijkstra -> AC.
What is the state of vertex?
dist[x][y] = (minimal number of steps, maximum energy left)
Thanks problemsetters for beautiful combination of ML and TL in problem 6 !!!11!11 I can't use neither static array nor vector)
You can emulate many dimensional arrays on 1-dimensional. It is very easy.