Two weeks ago I began streaming myself solving the CSES problemset on Youtube. The gimmick is that I code everything in C, and any code I submit must be written on stream. So, there are no standard data structures and algorithms, and no ICPC notebooks.
I try to explain the reasoning behind each solution and talk to whatever audience there is. Currently, each problem takes about 20 minutes between thinking + explanation on digital whiteboard + coding, but I guess it will take longer for the more difficult problems on the site.
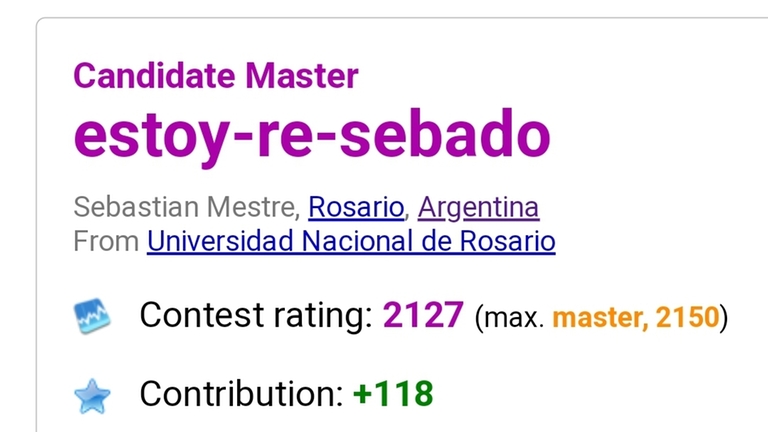
Credentials: I went to IOI three times (Japan, Azerbaijan, Singapore), ICPC World Finals two times (Egypt, Kazakhstan) and have a max rating of 2150 on Codeforces (although my rating sucks now because I don't take contests seriously anymore). Besides, I've been an OI coach for four years and a TA at my university for three, so I think I'm pretty decent at explaining stuff.
The streams have mostly been at 6pm (UTC-3) on random days, but I'm trying to set up a fixed schedule, so I'd appreciate some suggestions.
Check out my past streams at https://www.youtube.com/@smestre/streams
I would be pretty great of you if you left a comment or suggested some content ideas!