


At last!
The problem is 65A - Harry Potter and Three Spells, if you're curious.
Apparently, thinking before coding helps.
What is the longest it took you to upsolve a problem?
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 166 |
| 2 | maomao90 | 163 |
| 2 | Um_nik | 163 |
| 4 | atcoder_official | 161 |
| 5 | adamant | 160 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | nor | 153 |
| 9 | Dominater069 | 153 |
At last!
The problem is 65A - Harry Potter and Three Spells, if you're curious.
Apparently, thinking before coding helps.
What is the longest it took you to upsolve a problem?
I've bumped into this blog post by imtiyazrasool92 (unfortunately, it's already deleted due to downvotes). They've found out that simply declaring a global variable called read makes your program behave strangely on Codeforces: the outcome of 130645392 is RUNTIME_ERROR, Exit code is 2147483647, and here is the code:
#include <iostream>
int read;
int main(){
std::ios_base::sync_with_stdio(false);
std::cin >> read;
}
I was unable to minimize the example any further.
The original post was even more interesting: 130642683 is Accepted, but 130643108 is Runtime Error all of a sudden.
The compiler on Codeforces is G++17 9.2.0 (64 bit, msys2). However, I was able to reproduce the issue both on my local machine (g++ (Rev2, Built by MSYS2 project) 10.3.0) and the latest GCC on Godbolt as long as the -static key is used for compilation just like on Codeforces. Clang is also affected.
It looks like the read variable here replaces the standard Linux read function (which is emulated by msys2). Here is a symmetrical example:
#include <iostream>
int write;
int main(){
std::ios_base::sync_with_stdio(false);
std::cout << 10;
}
And here is one more (130646314), although now I at least get some warnings:
int malloc;
int main(){
}
a.cpp:1:5: warning: built-in function 'malloc' declared as non-function [-Wbuiltin-declaration-mismatch]
1 | int malloc;
| ^~~~~~
My understanding is that all these examples invoke ODR violation, which makes the program ill-formed (invalid) without any requirements on the compiler to emit the error. However, I am not sure, so I asked on StackOverflow.
Any other ideas?
Hi everyone!
I'd like to present you a prototype of Visual Studio plugin which was developed by a student from my university as a coursework. Yielding floor to her:
GraphAlgorithmRenderer is an experimental Visual Studio extension for debugging and visualizing graph algorithms. It takes a description of graph nodes, edges and their properties, such as color and label, and renders a corresponding graph. The graph is refreshed automatically when you step in debugger. Graph config can be serialized to JSON and deserialized back.
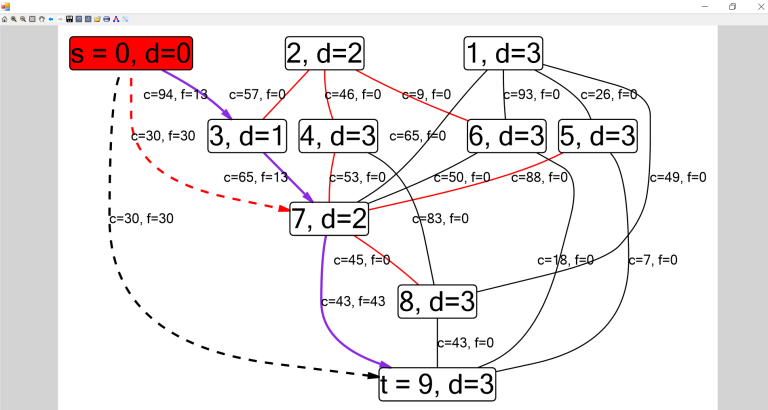
В последние недели или даже месяцы я заметил, что сломался мой сценарий использования Codeforces:
В чём выражается поломка: из примерно 5-10 открытых вкладок половина оказывается пустой. Пустой в следующем смысле: заголовок вкладки присутствует, посмотреть исходный код можно, однако сама страница целиком белая. DOM-дерево что-то содержит, но не слишком много, причём высота <body> оказывается нулевой:
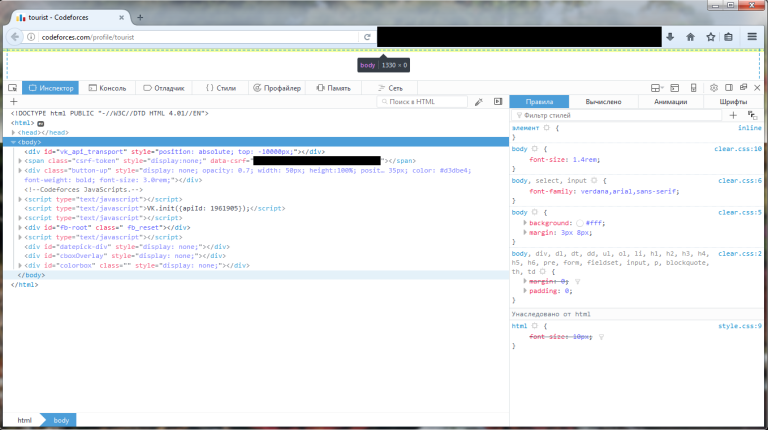
Для сравнения, вот та же страница, отобразившаяся нормально (обратите внимание, что появился <div id="body"> и несколько скриптов):
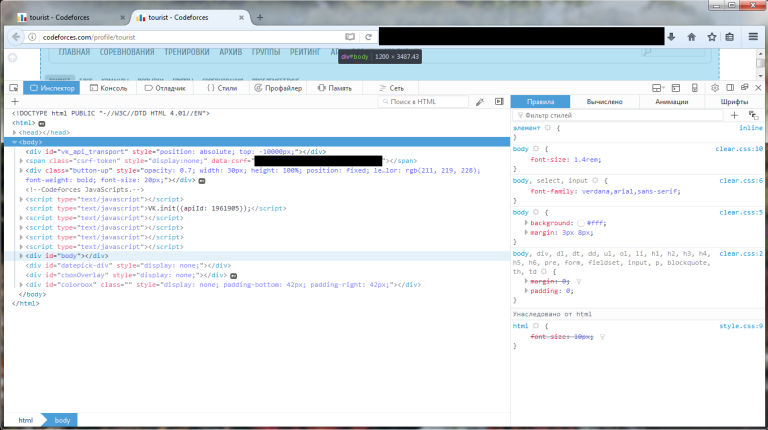
Проблема воспроизводится следующим образом:
firefox -P -no-remote и новый профиль — никаких странных кук на других сайтах). Однако в приватном режиме не воспроизводится.У меня есть подозрение, что тут как-то замешаны куки, которые ставит либо Codeforces, либо кто-то из скриптов аналитики/лайков.
Всем привет.
А есть ли тут люди, которые собеседовались/стажировались/работали в Samsung (хоть в Сеуле, хоть в других офисах) на позиции, связанные с программированием? Мне кажется особо вероятным, что этим занимались участники Всесибирской олимпиады — её какое-то время спонсировал Samsung и они собирали у желающих контакты.
Если есть — можете поделиться своими впечатлениями или мыслями? Особенно ценно, если есть возможность сравнивать с европейским/американским опытом.
Hello everyone.
Two years ago there was a post titled "Submitting IOI problems" and my comment there. I offered everyone to contact me via PM on Codeforces to get the access and be able to solve problems from past IOIs (starting with IOI 2003). What was important here is that PavelKunyavskiy and me took effort and made the system as similar to what was used on particular IOI as we could, including:
So far it was a closed judge available upon request only. As far as I remember, I've granted access to everyone who've asked — 150+ persons. Time flows and the judge eventually migrated to Yandex.Contest (the system used for Yandex.Algorithm) with help of lperovskaya. It still supports all of the above, but the registration is open for everyone and IOI 2015 is available there. Feel free to join!
Unfortunately, it's still a beta version and there are still some issues: no problem statements are visible in the interface, some labels may be in Russian only and graders for Pascal and Java may be non-working in some problems (C++ should work everywhere, though). Note that we use slightly different conventions for graders from what was on IOI (for the sake of consistency among all IOIs). You can download an archive with example solutions by clicking on the "Download" button right to the "Jury messages" link. If the button is not here, there is no archive with example solutions yet, but the format of graders should be very similar among all problems and we didn't change signatures of functions from IOI, so it should be fairly easy to "restore" the format.
I hope that will help all of you who are preparing for upcoming IOIs! By the way, if you have not advanced to IOI this year, I would highly recommend you to avoid reading several IOIs so you will have good problems preparing for IOI next year. It's hard to find good IOI-like problems.
I've just discovered this question on Quora: What is the story behind your username at CodeForces?. I guess it'd be pretty interesting to hear stories from top participants. For instance, my handle's history is already described there.
This blog is dedicated to everyone who don't have Quora account, so you can share your histories and comments here.
I personally would love to hear stories from tourist, rng_58 and YuukaKazami from current top-10.
Hello everyone.
Right now I'm settings up APIO 2011 contest for training purposes. It seems to me like test data (answers, to be precise) in problems 'Guess My Word' and 'Table Coloring' are broken. I have three solutions from three different people for the latter problem and they produce the same answers for tests 10, 12, 14, 16 and 18 — zero, while the reference answer is non-zero. For the 'Guess my Word' problem I have two solutions: one fast and one brute-force with memoization which I wrote by myself several minutes ago. These two solutions produce same output on tests 1-16, but they both produce 'No' on some test cases where official test data says 'Yes'.
Does anyone have information about validity of this test data or some solutions which I can test with too?
Thank you.
Есть довольно известная проблема с компиляцией нативных решений под Windows: если выделяются слишком большие статические массивы (или возникает какая-нибудь похожая проблема в процессе запуска), то проверяющая система может пометить посылку как "убившую систему" и не выдать участнику никакого вердикта. Например, раньше в системе Testsys это вызывало вердикт Failed To Test (и никакой информации участнику), на Codeforces — отказ тестирования, в PCMS2 и сейчас есть проблемы. Пример кода:
int data[(int)2.1e9 / sizeof(int)];
main() {}
Думаю, что всем мало-мальски знакомым с запуском процессов Windows очевидно, что с этим делать — попробовать запустить при компиляции и, возможно, выдать Compilation Error с отчётом. Похоже, что всем, кроме меня, было лень этим заняться и вот результат моих трудов, уже трудится на Codeforces. Если у вас тоже есть своя проверяющая система, вы можете запускать это приложение (или же просто скопировать код из него) после компилятора для проверки exe на корректность. В случае чего можно выдать сообщение пользователю с подсказкой "проверьте, пожалуйста, на большие массивы".
При использовании testexe никакой пользовательский код не запускается, процесс полностью замораживается операционной системой после успешной загрузки и еще до начала выполнения каких-либо инструкций (параметр CREATE_SUSPENDED).
Всем добрый день.
На прошлой неделе в Санкт-Петербурге начались традиционные учебно-тренировочные сборы школьников перед Всероссийской олимпиадой. Когда-то они выполняли отборочную роль, сейчас это лишь тренировки и учёба вместо школы. В пятницу я решил повторить свою прошлогоднюю лекцию про то, как вести себя на контестах и что может помочь/мешать решать задачи/набирать баллы, кроме знания алгоритмов. Алгоритмы рассказывают везде: и на e-maxx.ru, и в ЛКШ, и на Хабре, и на Codeforces. А вот никакой общедоступной информации на тему "а как организовать себя на контесте" я не видел. Когда я был школьником, разве что иногда кто-нибудь из преподавателей мимолётом замечал, что неплохо бы читать все задачи в первые минуты и писать заглушки когда-нибудь в течение контеста, потому что "напишете заглушки по каждой из шести задач — будет второй диплом на Всеросе".
Вся доступная мне информация собиралась, утрясалась и в прошлом году я решил прочитать лекцию на Петербургских сборах. Мне показалось, что никто не уснул, а информация оказалось полезной и в этом году лекция была повторена с небольшими улучшениями и записью на камеру. Представляю на суд общественности запись лекции и шпаргалку, по которой я читал.
В этом посте речь пойдёт о тестировании еще одного типа нестандартных задач. Они иногда встречаются на Всероссийских сборах школьников, а также на каждом Codechef Long Contest. Я говорю о неточных задачах, в которых участник оценивается относительно лучшего в некотором смысле решения среди жюри и всех участников. Обычно тесты оцениваются независимо, а оценка за тест — некая функция от "хорошести" решения участника и лучшего результата на этом тесте.
На данный момент поддержка таких задач в известных мне системах (Testsys, PCMS2, eJudge) возможна лишь костылём. Например, используется ровно один judge/invoker и на нём же в специальных файликах хранятся текущие лучшие результаты по каждому из тестов. После конца контеста требуется перетестировать все посылки, чтобы каждая была оценена исходя из глобально лучшего ответа, а не лучшего на момент посылки. Конечно, вместо этого можно скриптами подправить логи тестирования, но этот костыль тоже не блещет красотой.
Так как в существующих условиях нормально реализовать поддержку таких задач не представляется возможным (например, отсутствует хоть какая-то возможность влияния одних решений на результат других), я предлагаю разработать общий "стандарт" для написания и тестирования таких задач.
Итак, предложения (спасибо Gassa за помощь при формулировке и разработке):
Можно считать, что для выставления оценки за тест достаточно некоторой информации об ответе, меньшей, чем сам ответ (назовём её целевой функцией). Я не видел ни одной задачи, где это не было бы числом (например, длина пути коммивояжёра). Тем не менее, "с заделом на будущее" можно считать эту информацию последовательностью чисел и строк (сравниваются лексикографически). Последовательности также сравниваются лексикографически. Что при этом считать лучшим ответом — параметр задачи (например, надо минимизировать первый элемент, а при равенстве — максимизировать второй и т.д.). Погрешности сравнения вещественных чисел выставляются как параметры задачи, возможно, с некоторыми умолчаниями.
Хочется избавиться от необходимости перетестирования/ручной правки логов в конце/процессе контеста. Для этого предлагается отделить функциональность выставления баллов за тест от чекера. На чекер ложится обязанность выставить WA/PE/OK (вердикт PC/Partially Correct убирается) и выдать в комментарии значение целевой функции. Разумеется, не хочется терять комментарий в его стандартном смысле, поэтому предлагаю выводить в формате <комментарий><перевод строки><значение целевой функции>. Например: Looks good\n123 abacaba 44.5 При этом чекеру совершенно незачем знать текущий лучший ответ, и пропадает необходимость передавать его на тестирующую машину.
Таким образом, тестирующая система для получения фактического балла за тест (мне кажется, лучше выдавать процент от максимально возможного балла за тест, нежели сами баллы) должна запустить программу выставления баллов (назову её valuer по аналогии с ejudge) и передать ей на вход значение целевой функции участника и лучшее значение целевой функции.
Также тестирующая система для каждого теста (тесты стоит различать по хэшу, а не по номеру и дате изменения файла) хранит лучшее значение целевой функции и файл с ответом, на котором это значение было достигнуто. Последнее рекомендуется на случай проверки руками.
Исчезает необходимость перетестирования в конце контеста: достаточно еще раз запустить valuer для каждой посылки.
Впрочем, у меня остались некоторые неразрешённые вопросы:
Для выставления баллов за решение в текущей модели требуется довольно дорогостоящий запуск отдельного процесса. Мне не хочется запускать "чужой код" вне песочницы, поэтому тратится еще и время тестирующей машины. Возможное решение: использовать для написания valuer'а некоторого популярного/простого скриптового языка (например, EcmaScript/JavaScript или Lua), который легко проинтерпретировать и ограничить в правах. Тогда можно будет запускать его хоть после каждого сабмита и показывать результаты онлайн.
Если брать скриптовой язык — то какой? Хотелось бы выбрать один на всех. EcmaScript, как мне кажется, более известен и больше похож на C/C++/Java. С другой стороны, существующие интерпретаторы EcmaScript довольно громоздки. Lua же предоставляет легковесный интерпретатор с привязками ко многим языкам (C++, Delphi, Java, Python), однако он не слишком популярен и использует другой синтаксис (например, end вместо фигурных скобок, комментарии двойными дефисами и прочее). В остальном языки довольно схожи.
Прошу высказаться всех интересующихся, в особенности разработчиков тестирующих систем. Надеюсь на продуктивное обсуждение.
UPD: выложил пример чекера и valuer'а на C++ для задачи о коммивояжёре. Также есть пример valuer'а на javascript.
В конфиг testsys'а для такой задачи могут добавиться такие строчки:
# Целевая функция состоит ровно из одного токена, который надо минимизировать
# В случае большего количества токенов строка может выглядеть как "<<><"
DynamicScoringComparator = "<";
# DynamicScoringAbsoluteEps = 0.000000001; # По умолчанию
# DynamicScoringRelativeEps = 0.000000001; # По умолчанию
DynamicScoringValuer = $probdir\valuer.exe
На Codeforces уже поднимались темы об интерактивных задачах (первая и вторая).
В этой теме мне хочется поднять вопрос о вердиктах в интерактивных задачах (с которыми довольно часто возникают проблемы) и предложить дополнение к алгоритму тестирования, которое позволит выставлять их практически не завися от прихотей ОС (проблема, поднятая NALP в этой теме). Также будет показан код под Windows, реализующий это дополнение.
В самом начале хочется спросить: а как, вообще говоря, выставляются вердикты в обычных задачах? Базовой аксиомой является "сначала решение корректно завершается, а потом проверяется ответ". Таким образом, даже если решение вывело (не)корректный ответ в выходной файл, а потом завершилось с ненулевым кодом возврата (либо зависло), система не станет это проверять, а просто скажет RTE/TL.
В интерактивных задачах эта аксиома не работает. Например, если в процессе какой-то игры участник выводит несуществующий ход, продолжать взаимодействие не имеет смысла и надо выдать WA. Я предлагаю взять за аксиому следующее: "в первый момент времени, когда стало возможным выдать вердикт, отличный от OK, выполнение должно прерываться с очевидным вердиктом". Рассмотрим несколько примеров:
Участник вывел неверный ход и ждёт ответа чекера. Это очевидный WA.
Участник вывел неверный ход, понял, что сам дурак, и завершился с RTE.
Участник в процессе вывода вышел за границу массива, вывел бред и завершился с RTE.
Я утверждаю, что ситуации 2 и 3 в принципе неотличимы. Проверяющая система не может однозначно определить, вывел ли участник бред из-за RTE или же он случился строго после. Поэтому выставляется вердикт WA, который случился в момент вывода в stdout, что произошло раньше, чем RTE, который случился в момент завершения программы. В частности, при изменении задачи на интерактивную, могут поменяться получаемые вердикты: любой из них (TL/RTE/ML) может поменяться на WA. Это довольно неинтуитивно после стандартных задач. В качестве альтернативы после завершения интерактора можно некоторое время (до IL/TL) ожидать падения решения и, если оно произойдёт, поставить RTE. Это будет чуть ближе к стандартным задачам в том смысле, что в случае падения решение не будет проверяться его последний ответ. Это место еще стоит обсудить.
Также хочется отметить сложность в отличии вердиктов Idleness Limit Exceeded и WA/PE. Первый легко получить, если забыть fflush. Однако представим себе ситуацию, в которой участник по каким-то причинам вывел четыре числа вместо пяти и начал ждать ответа интерактора. В этом случае налицо нарушение протокола взаимодействия и хочется выставить WA/PE. Однако с точки зрения тестирующей системы ситуации отличаются только наличием вывода "в последнее время", что непонятно, как формализовать. Есть предложения? Мне лично хочется оставить как есть и ничего не придумывать.
Теперь перейдём к решению старых проблем. В первой теме MikeMirzayanov предложил алгоритм тестирования задач. Вкратце:
Параллельно с решением запускается интерактор, который имеет доступ к тесту (и ответу, если такой есть) и взаимодействует с решением. В случае нарушения протокола/заведомо неверного ответа он завершает работу. Если всё в порядке, то отдельно запускается чекер, который проверяет ответ, выведенный интерактором в файл вывода (в некоторых задачах чекер пустой и несодержателен — всё проверяет интерактор).
Если первым завершается решение, то либо сразу ставится вердикт из-за некорректного завершения (RTE/TL/ML), либо ожидается завершение интерактора, после чего выставляется вердикт, соответствующий результату работы интерактора/чекера.
Если первым завершается интерактор, то либо сразу ставится вердикт WA/PE, либо ожидается корректное завершение решения и запускается чекер.
В отдельном посте NALP указал на довольно существенный недостаток системы в реальных условиях: стандартные средства ОС не дают возможности точно определить, какой процесс завершился первым (да и не очень понятно, что это такое в многозадачной среде). Поэтому с точки зрения проверяющей системы ситуации "решение вывело WA, интерактор закрылся, решение упало с RTE, так как не смогло считать" и "решение упало, интерактор сказал WA, так как поток закрылся" неотличимы: решение завершилось некорректно, интерактор завершился с кодом возврата WA.
Теперь я хочу предложить точное и стабильное решение последней проблемы. Для этого сделаю два предположения:
При попытке чтения оба процесса (не поток, а весь процесс) полностью блокируются. Обычно использование многопоточности на олимпиадах либо запрещено, либо бессмысленно из-за подсчёта процессорного времени. Ситуации, в которой потребуется неблокирующий ввод в задаче, я представить также не могу, так что я этот пункт считаю покрывающим вообще все задачи.
Даже после выставление вердикта ОК, интерактор не завершается, пока не получит EOF, чтобы проверить, что участник не вывел что-то лишнее.
Решение проблемы выставления вердикта состоит в следующем: при создании пайпов для взаимодействия решений, тестирующая система не закрывает свой хэндл на вывод в пайп. Таким образом, у каждого пайпа образуется не два, а три конца — по одному у решения, у интерактора и у системы. При завершении любого из двух процессов, пайп не закрывается и решение/интерактор не получают EOF, пока этого не захочет тестирующая система.
Итого, алгоритм получается такой:
Запустить параллельно интерактор и решение с замкнутыми друг на друга вводом-выводом. При этом необходимо сохранить открытые хэндлы в тестирующей системе.
Пусть первым завершился интерактор. Так как он должен был ждать EOF в случае OK, то он должен был завешиться с вердиктом WA, который мы и выставляем (либо, как альтернативное решение, надо подождать и проверить отсутсвие RTE).
Значит, первым завершилось решение. Если решение завершилось корректно, мы закрываем хэндлы, интерактор получает EOF и завершается с некоторым вердиктом, который мы возвращаем как результат проверки. Если же оно завершилось некорректно, то возможно два варианта: либо это произошло вскоре после получения WA (и интерактор должен скоро завершиться), либо нет. Чтобы отличить WA/RTE в этой ситуации, надо проверить, что интерактор не ждёт ввода (т.е., тратит процессорное время). Если ждёт — ставим RTE, если делает что-то осмысленное — ждём его завершения и ставим вердикт.
Эта идея осуществлена в написанной мной для демонстрации утилите, которую можно скачать здесь. Она следует концепции "выставляем то, что случилось раньше" и не ждёт RTE после завершения интерактора с WA, зато ожидает завершения интерактора в случае падения решения.
Прошу высказать свои мысли по поводу дополненной схемы, возможности её реализации в других ОС, а также любую критику по поводу высказанных мыслей.
Довольно странно, что никто не создал пост для обсуждения. Сейчас заканчивается мартовский раунд USACO 2012. Желающие еще могут начать участие в течениие целых 18.5 часов. Предлагаю после окончания обсуждать тут задачи.
Всем привет.
Меня достало прокручивать страницу блога в поисках новых комментариев, а заходить в "прямой эфир" не всегда удобно, поэтому написал userscript, который добавляет справа страницы кнопки перемотки по новым комментариям.
Работает в Firefox (надо поставить плагин GreaseMonkey), Chrome. Скорее всего, работает в Opera и чем-нибудь еще - никакого специфичного API нет.
Установить можно по ссылке. Если выдаётся исходник - значит, Ваш браузер не поддерживает userscripts.
О багах и предложениях можно отписываться тут.
UPD: теперь стало возможным просматривать родительский комментарий при наведении мышки на "^". Клик по-прежнему работает.
UPD2: создал репозиторий на GitHub.
На Росолимпе появились тесты к прошлогоднему региону. Заодно выложил заочный этап заочки того же года.
Всё там же, где обычно: http://yeputons.net/tsweb/. Если кому-нибудь еще надо, то регистрируемся и сдаём. Можно переключаться между контестами ("List of all contests"). Система следующая: вы получаете результат выполнения программы на тестах из примера (и на online-группе, если такая есть), и, если хотите, можете открыть полные детальные результаты (как на IOI в этом году, кнопка "Use token"). Если программа не прошла примеры - она не тестируется вообще.
Можно разобрать четыре случая, а можно заметить, что если обозначить front/back за 0/1 (b), а из a вычесть единицу, то a XOR b будет ответом (0/1). Время и пямять - O(1).
Решается "в лоб" одним циклом: пока k-й вопрос сыгран, увеличить k на один, и, если k > n, то k = 1. Время и пямять - O(n).
Одним из решений было написать ровно то, что просят в условии. Итераций Винни-Пуха будет не более 3n (к каждой банке он обращается не более 3-х раз), каждую итерацию можно выполнить за O(n) (поиск максимума в массиве). Время - O(n2) ≈ 104 операций, память - O(n).
Но есть решение короче: давайте заметим, что порядок поедания мёда ни на что не влияет. Теперь посмотрим на то, сколько мёда из каждой банки съест Винни-Пух, а сколько оставит Пятачку. Нетрудно понять, что если ai > = 3k, то Винни-Пух оставит Пятачку ai - 3k килограмм, а если ai < 3k, то 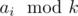 . Теперь решение задачи - один цикл. Время и память - O(n).
. Теперь решение задачи - один цикл. Время и память - O(n).
Сегодня, в четверг, 13 октября 2011 года в 15:02 по Москве состоится 521-й TopCoder Single Round Match (время в других городах).
Так как остальные задачи я не то что не пытался решить, а даже не читал, публикую те решения, которые узнал
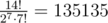 , что, очевидно даже при отсечении на последнем шаге рекурсии, влезает в TL.
, что, очевидно даже при отсечении на последнем шаге рекурсии, влезает в TL.Google Code Jam - очередное всемирное соревнование по спортивному программированию (язык - только английский). Для участния нужно иметь Google-аккаунт, зарегистрироваться и принять участие в квалификационном раунде, который продлится до трёх часов ночи (по Москве) сегодняшнего дня.
Итак, правила:
Добрый вечер.
Пару дней назад опубликовал статью на Хабре про БПФ. Постарался объяснить и доказать всё без матриц (как на e-maxx), потому что не умею с ними еще работать на интуитивном уровне. Там точно также есть код и оптимизации (кстати, одной очень важной - прекалк корней, на e-maxx нет).
Если кому-нибудь помогло разобраться - буду рад.
Вопрос: что есть сабж?
Откуда взял: книжка, которую наказали купить и составить по ней план теорподготовки к IOI.







