


Adiv2
Для решения задачи будем хранить два массива hused[j] и vused[j] размера n, изначально заполненных false. Будем обрабатывать перекрестки в списке от 1-го к n-му, и если для i-го перекрестка оба значения hused[hi] и vused[vi] равны false , i-ый день нужно добавить к ответу и установить значения hused[hi] и vused[vi] в true, означающих, что hi-ая горизонтальная и vi-ая вертикальная теперь заасфальтирована, а в противном случае нужно просто пропустить очередной перекресток.
Такое решение работает за O(n2).
Авторское решение: 13390628
Bdiv2
Чтобы получить оптимальный ответ, роботу нужно двигаться от первого компьютера к последнему, затем от последнего к первому, потом опять от первого к последнему, и т.д., попутно собирая те части информации, которые он может собрать на момент нахождения рядом с компьютером. Таким образом робот будет по максимуму использовать ресурсы, затраченные на смену направления движения. Несмотря на наличие более быстрых решений, от участников требовалось лишь решение с асимптотикой O(n2).
Авторское решение: 13390612
Adiv1
Пусть ответ представляет собой массив a1 ≤ a2 ≤ ... ≤ an. Далее будем пользоваться тем, что gcd(ai, aj) ≤ amin(i, j).
Верно, что gcd(an, an) = an ≥ ai ≥ gcd(ai, aj) для любых 1 ≤ i, j ≤ n. Это значит, что an равен максимальному элементу таблицы. Запишем в ответ an максимальный ответ и удалим его из текущего набора элементов. После удаления gcd(an, an) в наборе будут содержаться gcd(ai, aj) для любых 1 ≤ i, j ≤ n, таких, что 1 ≤ min(i, j) ≤ n - 1.
Из последних двух неравенств следует, что gcd(ai, aj) ≤ amin(i, j) ≤ an - 1 = gcd(an - 1, an - 1). Поскольку в наборе содержится gcd(an - 1, an - 1), максимальный элемент в наборе равен an - 1. Поскольку an уже известен, удалим из набора gcd(an - 1, an - 1), gcd(an - 1, an), gcd(an, an - 1) . Теперь в наборе содержатся gcd(ai, aj), для любых 1 ≤ i, j ≤ n таких, что 1 ≤ min(i, j) ≤ n - 2.
Далее повторим это операцию для каждого k from n - 2 to 1, устанавливая ak равным максимальному элементу в оставшемся наборе и удаляя gcd(ak, ak), gcd(ai, ak), gcd(ak, ai) для всех k < i ≤ n из набора.
С помощью математической индукции нетрудно доказать корректность такого алгоритма. Чтобы быстро выполнять удаление и получение максимального элемента в наборе, можно использовать, например, структуры map или set, что позволит реализовать решение с асимптотикой 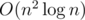 .
.
Авторское решение: 13390679
Bdiv1
Можно посчитать матрицу размера n × n mt[i][j] — длина наибольшей неубывающей подпоследовательности в массиве a1, a2, ..., an, начинающейся с элемента, не меньшего ai и заканчивающейся непосредственно в элементе aj.
Теперь, если мы имеем две матрицы размера n × n A[i][j] (ответ для массива a1, a2, ..., apn начинающегося с элемента, не меньшего ai и заканчивающейся элементом aj в последнем блоке массива (a(p - 1)n + 1, ..., apn) и B[i][j] (ответ для массива a1, a2, ..., aqn ), то произведение этих матриц
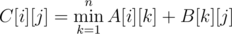
даст подобную матрицу, но для массива из p + q блоков. Так как такое произведение матриц является ассоциативным, воспользуемся быстрым возведением матрицы в степень для подсчета M[i][j] (ответ для массива a1, a2, ..., anT) — матрица mt[i][j] в степени T. Ответ на задачу — максимум матрицы M. Такое решение имеет асимптотику 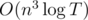 .
.
Авторское решение (с матрицами): 13390660
Существует альтернативное решение. Так как a1, a2, ..., anT содержит максимум n различных элементов, любая его неубывающая подпоследовательность содержит максимум n - 1 последовательных возрастающих соседних элементов. Пользуясь этим фактом, будем считать стандартное динамическое программирование на первых n блоках массива (a1, ..., an2) и на n последних блоках массива (anT - n + 1, ..., anT). Все остальные блоки (а их T - 2n) между ними будут порождать равные элементы в результирующей неубывающей подпоследовательности.
Таким образом, для фиксированного ai, в котором заканчивается неубывающая подпоследовательность длины p массива из первых n блоков, и для фиксированного aj ≥ ai, в котором аналогичная подпоследовательность длины s на последних n блоках массива начинается, нужно обновить ответ величиной p + (T - 2n)count(ai) + s, где count(x) — количество вхождений x в массив a1, ..., an. Получаем решение за  .
.
Авторское решение ( с динамикой): 13390666
Cdiv1
Зафиксируем s и рассмотрим каждую пару (l, s). Тогда, если превосходящий подмассива содержит ai, то ai должен быть не меньше каждого aj такого, что 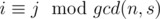 . Будем использовать этот факт и решать задачу для фиксированного g = gcd(n, s) (g|n). Для последующей проверки того, что ai может содержаться в превосходящем подмассиве, посчитаем для каждого 0 ≤ r < g
. Будем использовать этот факт и решать задачу для фиксированного g = gcd(n, s) (g|n). Для последующей проверки того, что ai может содержаться в превосходящем подмассиве, посчитаем для каждого 0 ≤ r < g
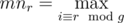 .
.
Каждый периодический подмассив состоит из 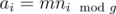 и только из них. Для нахождения количества таких подмассивов будем пользоваться методом двух указателей и для каждого подходящего ai такого, что
и только из них. Для нахождения количества таких подмассивов будем пользоваться методом двух указателей и для каждого подходящего ai такого, что 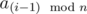 не является подходящим, найдем такое aj, что
не является подходящим, найдем такое aj, что 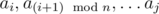 являются подходящими и
являются подходящими и 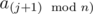 не является подходящим. Пусть представляет подотрезок из k элементов, т.е.
не является подходящим. Пусть представляет подотрезок из k элементов, т.е. 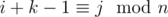 . Любой подотрезок этого подотрезка так же является превосходящим, поэтому к отрезкам длины 1, 2, ..., k мы должны прибавить k, k - 1, ..., 1 соответственно. Так как сумма всех k не превосходит n, можно циклом увеличивать нужные значения. Случай, когда все ai являются подходящими, нужно обрабатывать отдельно. После подсчета всех необходимых величин, мы должны добавить лишь те количества подотрезков длины x, для которых gcd(x, n) = g.
. Любой подотрезок этого подотрезка так же является превосходящим, поэтому к отрезкам длины 1, 2, ..., k мы должны прибавить k, k - 1, ..., 1 соответственно. Так как сумма всех k не превосходит n, можно циклом увеличивать нужные значения. Случай, когда все ai являются подходящими, нужно обрабатывать отдельно. После подсчета всех необходимых величин, мы должны добавить лишь те количества подотрезков длины x, для которых gcd(x, n) = g.
Описанное решение имеет асимптотику O(d(n)n), где d(n) — количество делителей n.
Авторское решение: 13390645
Ddiv1
It is a common fact that for a prime p and integer n maximum α, such that pα|n! is calculated as 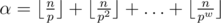 , where pw ≤ n < pw + 1. As soon as
, where pw ≤ n < pw + 1. As soon as 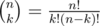 , the maximum α for
, the maximum α for 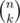 is calculated as
is calculated as 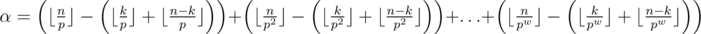 .
.
One could see, that if we consider numbers n, k and n - k in p-th based numeric system, rounded-down division by px means dropping last x digits of its p-th based representation. As soon as k + (n - k) = n, every i-th summand in α corresponds to carry in adding k to n - k in p-th numeric system from i - 1-th to i-th digit position and is to be 0 or 1.
First, let convert A given in statement from 10 to p-th numeric system. In case, if α is greater than number of digits in A in p-th numeric system, the answer is 0. Next we will calculate dynamic programming on A p-th based representation.
dp[i][x][e][r] — the answer for prefix of length i possible equal to prefix of A representation (indicator e), x-th power of p was already calculated, and there must be carry equal to r from current to previous position. One could calculate it by bruteforcing all of p2 variants of placing i-th digits in n and k according to r and e and i-th digit of A, and make a translation to next state. It can be avoided by noticing that the number of variants of placing digits is always a sum of arithmetic progression and can be calculated in O(1).
It's highly recommended to examine jury's solution with complexity O(|A|2 + |A|min(|A|, α)).
Jury's solution: 13390698
Ediv1
One could prove that the number of binary functions on 4 variables is equal to 224, and can be coded by storing a 24-bit binary mask, in which every bit is storing function value for corresponding variable set. It is true, that if maskf and maskg are correspond to functions f(A, B, C, D) and g(A, B, C, D), then function (f&g)(A, B, C, D) corresponds to maskf&maskg bitmask.
Now, we could parse expression given input into binary tree. I should notice that the number of non-list nodes of such tree is about 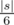 . Now, let's calculate dynamic programming on every vertex v — dp[v][mask] is the number of ways to place symbols in expression in the way that subtree of vertex v will correspond to function representing by mask. For list nodes such dynamic is calculated pretty straightforward by considering all possible mask values and matching it with the variable. One could easily recalculate it for one node using calculated answers for left and right subtree in 416 operations: dp[v][lmask|rmask] + = dp[l][lmask] * dp[r][rmask].
. Now, let's calculate dynamic programming on every vertex v — dp[v][mask] is the number of ways to place symbols in expression in the way that subtree of vertex v will correspond to function representing by mask. For list nodes such dynamic is calculated pretty straightforward by considering all possible mask values and matching it with the variable. One could easily recalculate it for one node using calculated answers for left and right subtree in 416 operations: dp[v][lmask|rmask] + = dp[l][lmask] * dp[r][rmask].
But all the task is how to make it faster. One could calculate s[mask], where s[mask] is equal to sum of all its submasks (the masks containing 1-bits only in positions where mask contains 1-bits) in 24·224 operations using following code:
for (int mask = 0; mask < (1 << 16); ++mask) s[mask] = dp[x][mask];
for (int i = 0; i < 16; ++i)
for (int mask = 0; mask < (1 << 16); ++mask)
if (!(mask & (1 << i))) s[mask ^ (1 << i)] += s[mask];
Let's calculate sl[mask] and sr[mask] for dp[l][mask] and dp[r][mask] respectively. If we will find s[mask] = sl[mask] * sr[mask], s[mask] will contain multiplications of values of pairs of masks from left and right dp's, which are submasks of mask. As soon as we need pairs, which in bitwise OR will give us exactly mask, we should exclude pairs, which in bitwise OR gives a submask of mask, not equal to mask. This gives us exclusion-inclusion principle idea. The formula of this will be
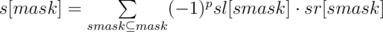 , where p is the parity of number of bits in mask^submask.
, where p is the parity of number of bits in mask^submask.
Such sum could be calculated with approach above, but subtracting instead of adding
for (int mask = 0; mask < (1 << 16); ++mask) s[mask] = sl[mask] * sr[mask];
for (int i = 0; i < 16; ++i)
for (int mask = 0; mask < (1 << 16); ++mask)
if (!(mask & (1 << i))) s[mask ^ (1 << i)] -= s[mask];
In such way we will recalculate dynamic for one vertex in about 3·24·216 operations.
Jury's solution: 13390713


