


NAIPC is coming up on April 15 (start time here). More information can be found on the site. The contest will be on Kattis on the 15th. About 15 hours later, it will be available as an open cup round as the Grand Prix of America. Please only participate in one of them, and don't discuss problems here until after the open cup round.
The deadline to register for the contest on Kattis is April 12th. You can register by following instructions on this site: http://naipc.uchicago.edu/2017/registration.html# You will need an ICPC account to register.
You can see previous NAIPC rounds here: 2015, 2016. 2016 is also available in the codeforces gym here: http://codeforces.net/gym/101002
UPD 1: The deadline to register is in a couple of days.
UPD 2: Both contests are now over
NAIPC standings: https://naipc17.kattis.com/standings
Open Cup standings: http://opentrains.snarknews.info/~ejudge/res/res10376
I'll update this one more time with solutions once they are up.
UPD 3: Test data is available here (solutions may show up later, but I'm not sure when): http://serjudging.vanb.org/?p=1050






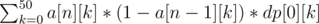
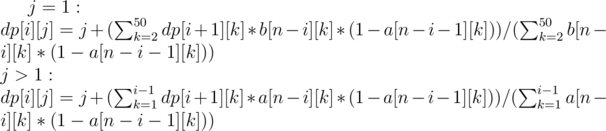

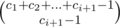 (minus one because we need to put one ball at the very end). Using this recurrence, we can solve for
(minus one because we need to put one ball at the very end). Using this recurrence, we can solve for 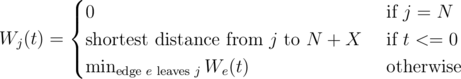
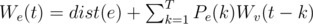
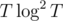 , which gives us a total runtime of
, which gives us a total runtime of 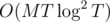 .
.