


Recently, I have met three problems which all need segment tree with interval updating (lazy propagation). I did not solve any of them on my own, but got inspired a lot from their solutions. I would like to share some of my thought about the ideas behind these three problems. If you are learning segment tree as well, hope that this could help a little.
Thought 1. It might seem from the first sight that the problem needs a huge number of interval updating, however it turns out that only O(N) or O(NlogN) is enough.
1) Problem https://codeforces.net/contest/438/problem/D. This problem asks to update an interval by module of some integer P while the query is to find the sum of any given interval. I really get stuck here. I think that, for any given interval, for the worst case, we have to deal with every element, and thus lazy propagation never works. However, there exists a wonderful trick! For any x and p(both positive integers), if p<=x, then x%p < x/2 holds, meaning that any element will be updated for at most O(logN) times. As there are O(N) elements, and each updating in segment tree costs O(logN), thus the total complexity is O(NlogNlogN).
2) Problem https://codeforces.net/contest/445/problem/E. In this problem, again, I got very confused at first, when it seems that each modification might contain a huge number of interval updating, and I can not figure out on earth how much such updating it needs. However, the key idea is amortised analysis! For any segment that is fully or partly covered, it contributes O(logN) complexity. Next, if a segment is fully covered, it "disappears" from then, and will not contribute any complexity, while for a partly covered segment, the covered part "disappears" as well and the other part "forms" a new segment. Therefore, after each "updating" operation, there are at most three new segments created, so the total number of updating is O(N+3M), which turns out to give linear complexity!
Thought 2. When updating an interval, brute force will update every element included within this interval, while lazy propagation saves complexity if the "updating information" could be represented by a constant number of variables.
1) Problem http://codeforces.net/contest/447/problem/E. This problem requires to add a Fibonacci sequence to some given interval. I have been quite familiar with adding some integer to an interval, where we could use an extra variable to store this integer, i.e., lazy propagation. But, this is the only pattern which I know, and I think there is only such a pattern, until this problem teaches me a lesson about how lazy propagation really works. Fibonacci sequence has a feature that, the n-th element could be represented by a weighted sum of the first and second element, which also applies for its prefix sum. Therefore, we could use two variables to store the first and second element for any interval, which is enough to implement lazy propagation. Similarly, by using this idea, we could also deal with some other sequences, like Arithmetic sequence, geometric series, and so on.
Finally, due to the limited space, most of the details about the solutions have been omitted, and some parts are perhaps not described clearly. So, if you are interested in this topic, or have any suggestion, or would like to discuss the solutions, I will be very glad and ready for that :D





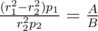 , which gives
, which gives 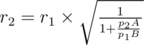 . Thus, we should find the maximum
. Thus, we should find the maximum 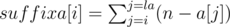 can be viewed as a suffix sum. When we reach a
can be viewed as a suffix sum. When we reach a 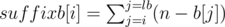 . Then, we move
. Then, we move 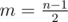 , and another vertical line crossing the
, and another vertical line crossing the 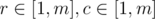 , then there will be totally
, then there will be totally 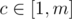 , then there will be
, then there will be 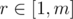 , then there will be
, then there will be 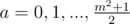 ,
, 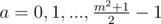 ,
, 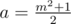 ,
, 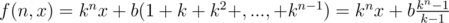 . Then, we can construct an inequality, and compute the answer.
. Then, we can construct an inequality, and compute the answer.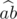 .
.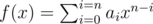 , it can be written as
, it can be written as 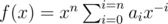 (
(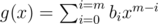 is similar). Thus, as
is similar). Thus, as 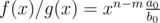 , we can further reduce the term
, we can further reduce the term 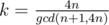 .
.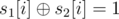 ,
, 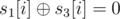 , and so on. Similarly, for a column (0 1 1 0), it gives (1 1 0 0 1 1). Based on the above examples, we can see that the column can have
, and so on. Similarly, for a column (0 1 1 0), it gives (1 1 0 0 1 1). Based on the above examples, we can see that the column can have 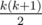 while not exceeding
while not exceeding 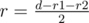 .
.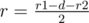 .
.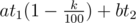 and
and 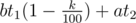 is larger. We can rewrite
is larger. We can rewrite 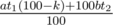 , and thus it is sufficient to compare their numerators to determine which one has a larger value. Similarly, sorting should also be implemented in this manner, i.e., we only compare their numerators. Finally, when we output
, and thus it is sufficient to compare their numerators to determine which one has a larger value. Similarly, sorting should also be implemented in this manner, i.e., we only compare their numerators. Finally, when we output 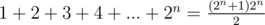 .
.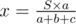 ,
, 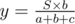 ,
, 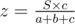 . If
. If 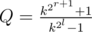 , and we should compute the inverse of
, and we should compute the inverse of 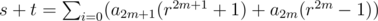 . Note that
. Note that 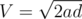 . Thus, for buses whose maximum speed
. Thus, for buses whose maximum speed 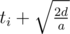 , where
, where 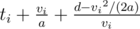 .
. 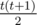 to the final answer, where
to the final answer, where 