Hello, Codeforces!
I want to share an algorithm and implementation for the Indexing Problem: given a text string $$$T$$$, we want to answer online queries of, given a pattern, how many times it occurs in the text.
For some query defined by a pattern $$$P$$$, the indexing problem can be solved using suffix arrays in $$$\mathcal O(|P| \log |T|)$$$ time, as described in edu and my other blog. Here, I will describe a solution in $$$\mathcal O(|P| + \log |T|)$$$ time, also using suffix arrays, from the original paper introducing the suffix array [1]. The description from the paper is good, although their pseudocode, it seems, has bugs.
Using suffix arrays makes sense (instead of suffix trees, for example) because they can be build in linear time, even if the alphabet is $$$\Theta(|T|)$$$. For large alphabets, suffix trees will always have an extra logarithmic factor in the time complexity, unless we use hashing... but who wants that, right?
UPD: this problem was also discussed in this blog.
The Indexing Algorithm
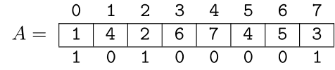
Now, for the solution. Remember that the indices where any pattern occurs in the text is a range in the suffix array. We will compute the first and last index of the range independently.
To optimize from the $$$\mathcal O(|P| \log |T|)$$$ time implementation (a simple binary search with $$$\mathcal O(|P|)$$$ time string comparison), we will use the $$$lcp$$$ information. We will use the type of binary search that maintains that the answer is in the open range $$$(L, R)$$$ [2].
At every iteration of the binary search, we maintain two values $$$l$$$ and $$$r$$$, the $$$lcp$$$ between $$$P$$$ and the suffixes $$$T_{sa[L]}$$$ and $$$T_{sa[R]}$$$, respectively. Here, we use the notation $$$T_i$$$ for the suffix of $$$T$$$ starting at index $$$i$$$. Also, $$$sa$$$ is the suffix array.
Now, we need to compute $$$lcp(P, T_{sa[M]})$$$, and then the next character will tell us what side of the binary search we need to go to. For that, let us assume that $$$l \geq r$$$ (the other case will be symmetric). We now compare $$$l$$$ with $$$lcp(T_{sa[L]}, T_{sa[M]})$$$ (assume we have this value precomputed). We have two cases:
- $$$lcp(T_{sa[L]}, T_{sa[M]}) < l$$$: in this case, $$$lcp(P, T_{sa[M]}) = lcp(T_{sa[L]}, T_{sa[M]})$$$, because $$$P$$$ matches $$$l$$$ characters from $$$T_{sa[L]}$$$, and $$$T_{sa[L]}$$$ matches less than $$$l$$$ characters from $$$T_{sa[M]}$$$.
- $$$lcp(T_{sa[L]}, T_{sa[M]}) \geq l$$$: now we can find the smallest $$$i > l$$$ such that $$$P[i] \neq T_{sa[M]}[i]$$$, and assign $$$lcp(P, T_{sa[M]}) = i$$$.
It turns out that if we do case 2 naively and update our $$$(l, r)$$$ accordingly, the total cost of these comparisons is $$$\mathcal O(|P|)$$$, because each time we increase $$$\max(l, r)$$$, and these values can only increase up to $$$|P|$$$. Also, on case case 1 we always go left on the binary search (because $$$r \leq lcp(T_{sa[L]}, T_{sa[M]}) < l$$$), thus maintaining or increasing the value of $$$r$$$. In fact, both $$$l$$$ and $$$r$$$ never decrease.
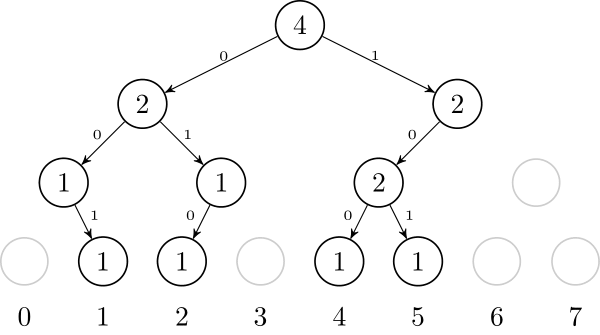
We are left to precomputing $$$L$$$_$$$lcp[M] = lcp(T_{sa[L]}, T_{sa[M]})$$$ and $$$R$$$_$$$lcp[M] = lcp(T_{sa[R]}, T_{sa[M]})$$$ for every possible range we visit in the binary search. But this is easy: we can just recursively go through every $$$(L, R)$$$ pair we can visit in a binary search, and store the $$$lcp$$$ value of the range. Note that the value of $$$M$$$ uniquely identifies the range.
The full code is seen below. The last boolean indicates if the first index of the range or the first index not in the range is to be computed. The number of occurrences is then the difference between the values. If $$$P$$$ does not occur in $$$T$$$, the code returns the empty range $$$[n, n)$$$. The last check in the code refers to the pattern not occurring (see next section).
Largest Occurring Prefix
Note that, at the end of the algorithm, k = max(l, r) is the largest prefix of $$$P$$$ that occurs in $$$T$$$. It is not hard to see that the algorithm actually runs in $$$\mathcal O(k + \log |T|)$$$. This allows us to compute, for example, the minimum size partition of $$$P$$$ such that every element occurs in $$$T$$$ in $$$\mathcal O(|P| \log |T|)$$$ time.
Example problem: 102428G - Gluing Pictures
Code: 285670319
References
[1]: Manber, U., & Myers, G. (1993). Suffix arrays: a new method for on-line string searches. siam Journal on Computing, 22(5), 935-948. [2]: https://codeforces.net/blog/entry/96699






 $$$\hspace{30pt}$$$
$$$\hspace{30pt}$$$